文章詳情頁
python - 標簽樹的下行遍歷如何跳過第一個標簽
瀏覽:115日期:2022-08-08 11:07:17
問題描述
爬取網頁用下行遍歷的找出了我要的標簽,但第一個的內容我是不要的用.children好像無法跳出第一個標簽
for tr in soup.find(id='endText').children: if tr.string is not None:a = tr.string
網頁的內容:
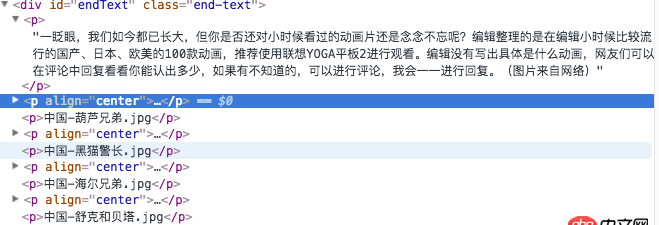 原鏈接:http://digi.163.com/14/1115/0...
原鏈接:http://digi.163.com/14/1115/0...
問題解答
回答1:p_list = list(soup.find(id='endText').find_all(’p’))for p in p_list[1:]: text = p.get_text() img = p.find('img') if img:print img.get(’src’) if text:print text
相關文章:
1. 數據庫 - Mysql的存儲過程真的是個坑!求助下面的存儲過程哪里錯啦,實在是找不到哪里的問題了。2. php傳對應的id值為什么傳不了啊有木有大神會的看我下方截圖3. 如何用筆記本上的apache做微信開發的服務器4. python - linux怎么在每天的凌晨2點執行一次這個log.py文件5. 關于mysql聯合查詢一對多的顯示結果問題6. 冒昧問一下,我這php代碼哪里出錯了???7. windows誤人子弟啊8. mysql優化 - MySQL如何為配置表建立索引?9. MySQL主鍵沖突時的更新操作和替換操作在功能上有什么差別(如圖)10. 實現bing搜索工具urlAPI提交
排行榜
 網公網安備
網公網安備