Python爬蟲爬取博客實現(xiàn)可視化過程解析
源碼:
from pyecharts import Barimport reimport requestsnum=0b=[]for i in range(1,11): link=’https://www.cnblogs.com/echoDetected/default.html?page=’+str(i) headers={’user-agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36’} r=requests.get(link,headers=headers) html=r.text post=re.findall(’<span class='post-view-count'>(.*?)</span>’,html)for i in post: i = i.replace('閱讀(', '') i = i.replace(')','') b.append(i) num=num+1columns=[]for i in range(1,num+1):#設置行名 columns.append(’博客’+str(i))#設置數(shù)據(jù)#設置柱狀圖的主標題與副標題bar = Bar('柱狀圖', '每個博客閱讀數(shù)量')#添加柱狀圖的數(shù)據(jù)及配置項,先行后列bar.add('閱讀量', columns, b, mark_line=['average'], mark_point=['max', 'min'])#生成本地文件(默認為.html文件)bar.render()
爬蟲不是重點,只是拿來爬閱讀數(shù)量,pyecharts是重點
這次爬的是我自己的博客,一共10頁,每頁10片文章,正好寫了100篇博客
pyecharts安裝:
pip install wheelpip install pyecharts==0.1.9.4
直接pip install pyecharts會下載最新版無法調(diào)用
注意點:pyecharts調(diào)用,貌似無法實現(xiàn)多個py文件一起調(diào)用(意思是編寫時不能在多個文件里出現(xiàn)import語句)
步驟解釋:
1.爬蟲爬取閱讀數(shù)
2.去除非法字符裝入新的數(shù)組
3.設置橫軸數(shù)據(jù),生成柱狀圖
4.在當前目錄下生成render.html,打開查看柱狀圖
結果:
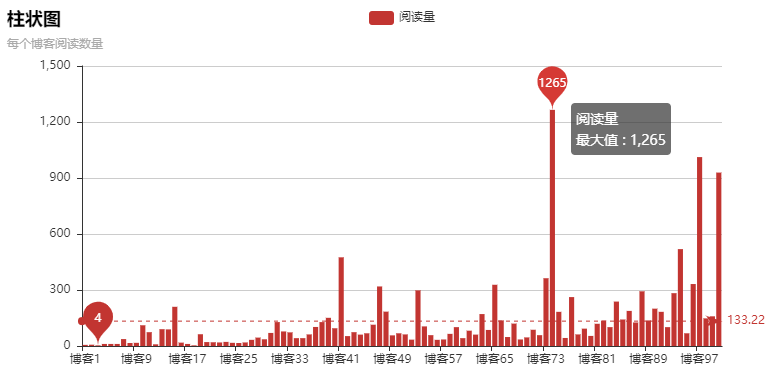
柱狀圖是動態(tài)的,不是靜態(tài)的
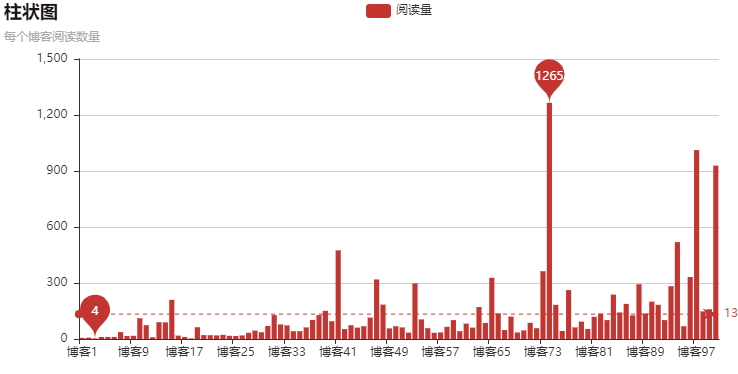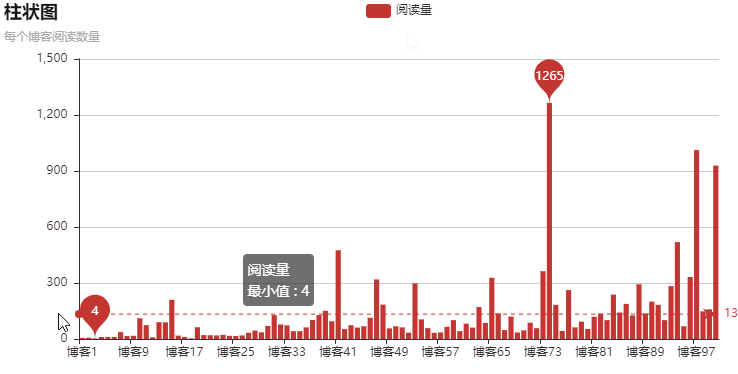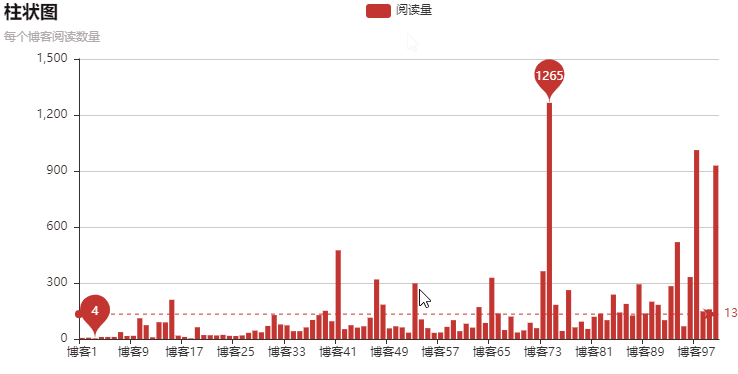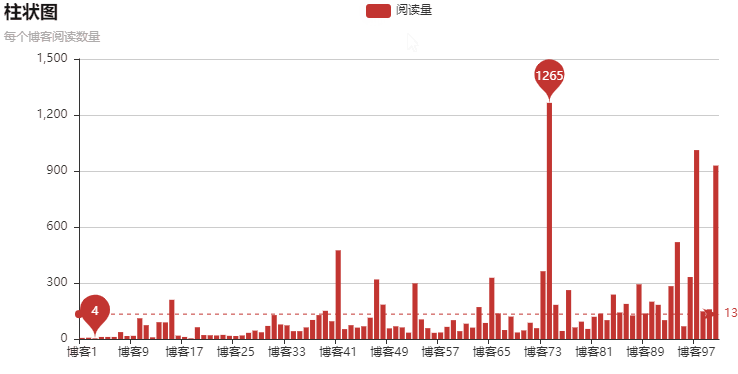
以上就是本文的全部內(nèi)容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關文章:
1. XML在語音合成中的應用2. jscript與vbscript 操作XML元素屬性的代碼3. 不要在HTML中濫用div4. HTML5實戰(zhàn)與剖析之觸摸事件(touchstart、touchmove和touchend)5. .NET Framework各版本(.NET2.0 3.0 3.5 4.0)區(qū)別6. ASP基礎入門第四篇(腳本變量、函數(shù)、過程和條件語句)7. ASP將數(shù)字轉中文數(shù)字(大寫金額)的函數(shù)8. XML入門的常見問題(三)9. php使用正則驗證密碼字段的復雜強度原理詳細講解 原創(chuàng)10. HTTP協(xié)議常用的請求頭和響應頭響應詳解說明(學習)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備