python利用Excel讀取和存儲測試數據完成接口自動化教程
http_request2.py用于發起http請求
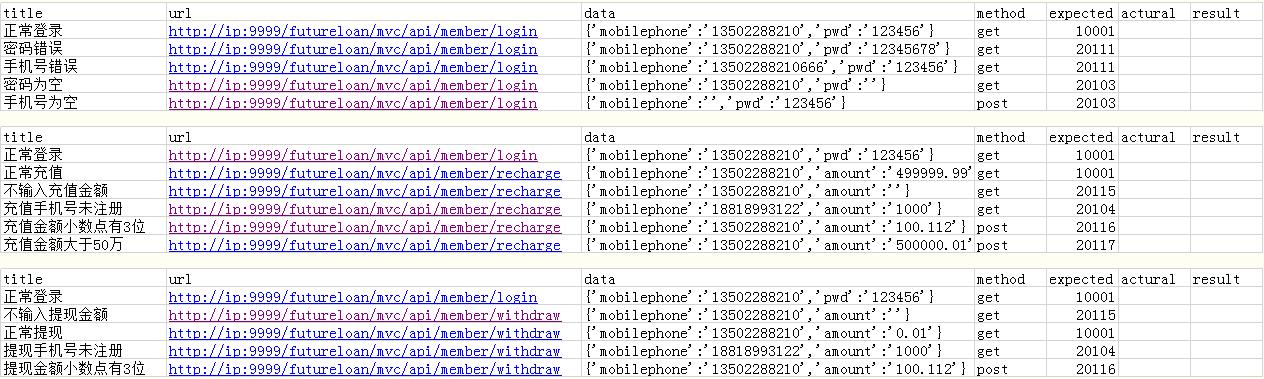
#讀取多條測試用例#1、導入requests模塊import requests#從 class_12_19.do_excel1導入read_data函數from do_excel2 import read_datafrom do_excel2 import write_datafrom do_excel2 import count_case#定義http請求函數COOKIE=Nonedef http_request2(method,url,data): if method==’get’: print(’發起一個get請求’) result=requests.get(url,data,cookies=COOKIE) else: print(’發起一個post請求’) result=requests.post(url,data,cookies=COOKIE) return result #返回響應體 # return result.json() #返回響應結果:結果是字典類型:{’status’: 1, ’code’: ’10001’, ’data’: None, ’msg’: ’登錄成功’}#從Excel讀取到多條測試數據sheets=[’login’,’recharge’,’withdraw’]for sheet1 in sheets: max_row=count_case(sheet1) print(max_row) for case_id in range(1,max_row): data=read_data(sheet1,case_id) print(’讀取到第{}條測試用例:’.format(data[0])) print(’測試數據 ’,data) #print(type(data[2])) #調用函數發起http請求 result=http_request2(data[4],data[2],eval(data[3])) print(’響應結果為 ’,result.json()) if result.cookies: COOKIE=result.cookies #將測試實際結果寫入excel #write_data(case_id+1,6,result[’code’]) write_data(sheet1,case_id+1,7,str(result.json())) #對比測試結果和期望結果 if result.json()[’code’]==str(data[5]): print(’測試通過’) #將用例執行結果寫入Excel write_data(sheet1,case_id+1,8,’Pass’) else: write_data(sheet1,case_id+1,8,’Fail’) print(’測試失敗’)
do_excel2.py完成對excel中用例的讀、寫、統計
# 導入load_workbookfrom openpyxl import load_workbook#讀取測試數據#將excel中每一條測試用例讀取到一個列表中#讀取一條測試用例——寫到一個函數中def read_data(sheet_name,case_id): # 打開excel workbook1=load_workbook(’test_case2.xlsx’) # 定位表單(test_data) sheet1=workbook1[sheet_name] print(sheet1) test_case=[] #用來存儲每一行數據,也就是一條測試用例 test_case.append(sheet1.cell(case_id+1,1).value) test_case.append(sheet1.cell(case_id+1,2).value) test_case.append(sheet1.cell(case_id+1,3).value) test_case.append(sheet1.cell(case_id+1,4).value) test_case.append(sheet1.cell(case_id+1,5).value) test_case.append(sheet1.cell(case_id+1,6).value) return test_case #將讀取到的用例返回#調用函數讀取第1條測試用例,并將返回結果保存在data中# data=read_data(1)# print(data)#將測試結果寫會exceldef write_data(sheet_name,row,col,value): workbook1=load_workbook(’test_case2.xlsx’) sheet=workbook1[sheet_name] sheet.cell(row,col).value=value workbook1.save(’test_case2.xlsx’)#統計測試用例的行數def count_case(sheet_name): workbook1=load_workbook(’test_case2.xlsx’) sheet=workbook1[sheet_name] max_row=sheet.max_row #統計測試用例的行數 return max_row
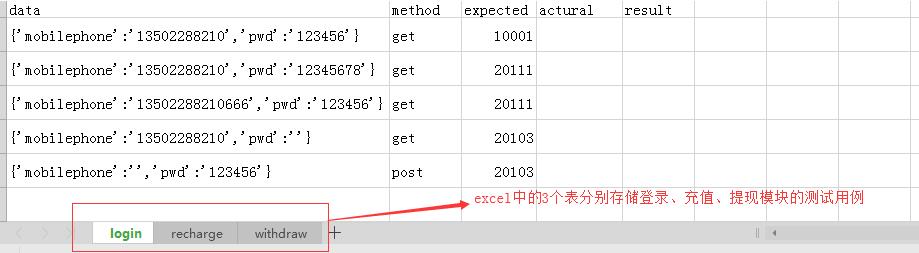
test_case2.xlsx存儲測試用例
補充知識:python用unittest+HTMLTestRunner+csv的框架測試并生成測試報告
直接貼代碼:
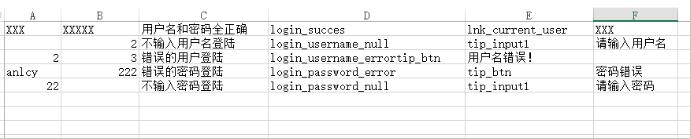
import csv # 導入scv庫,可以讀取csv文件from selenium import webdriverimport unittestfrom time import sleepimport timeimport osimport HTMLTestRunnerimport codecsimport sysdr = webdriver.Chrome()class testLo(unittest.TestCase): def setUp(self): pass def test_login(self): ’’’登陸測試’’’ path = ’F:Python_test’ # 要讀取的scv文件路徑 my_file = ’F:pythonprojectinterfaceTesttestFiless.csv’ # csv.reader()讀取csv文件, # Python3.X用open,Python2.X用file,’r’為讀取 # open(file,’r’)中’r’為讀取權限,w為寫入,還有rb,wd等涉及到編碼的讀寫屬性 #data = csv.reader(codecs.open(my_file, ’r’, encoding=’UTF-8’,errors= ’ignore’)) with codecs.open(my_file, ’r’, encoding=’UTF-8’,errors= ’ignore’) as f: data=csv.reader((line.replace(’x00’,’’) for line in f)) # for循環將讀取到的csv文件的內容一行行循環,這里定義了user變量(可自定義) # user[0]表示csv文件的第一列,user[1]表示第二列,user[N]表示第N列 # for循環有個缺點,就是一旦遇到錯誤,循環就停止,所以用try,except保證循環執行完 print(my_file) for user in data: print(user) dr.get(’https://passport.cnblogs.com/user/signin’) # dr.find_element_by_id(’input1’).clear() dr.find_element_by_id(’input1’).send_keys(user[0]) # dr.find_element_by_id(’input2’).clear() dr.find_element_by_id(’input2’).send_keys(user[1]) dr.find_element_by_id(’signin’).click() sleep(1) print(’n’ + ’測試項:’ + user[2]) dr.get_screenshot_as_file(path + user[3] + '.jpg') try: assert dr.find_element_by_id(user[4]).text try: error_message = dr.find_element_by_id(user[4]).text self.assertEqual(error_message, user[5]) print(’提示信息正確!預期值與實際值一致:’) print(’預期值:’ + user[5]) print(’實際值:’ + error_message) except: print(’提示信息錯誤!預期值與實際值不符:’) print(’預期值:’ + user[5]) print(’實際值:’ + error_message) except: print(’提示信息類型錯誤,請確認元素名稱是否正確!’) def tearDown(self): dr.refresh() # 關閉瀏覽器 dr.quit()if __name__ == '__main__': # 定義腳本標題,加u為了防止中文亂碼 report_title = u’登陸模塊測試報告’ # 定義腳本內容,加u為了防止中文亂碼 desc = u’登陸模塊測試報告詳情:’ # 定義date為日期,time為時間 date = time.strftime('%Y%m%d') time = time.strftime('%Y%m%d%H%M%S') # 定義path為文件路徑,目錄級別,可根據實際情況自定義修改 path = ’F:Python_test’ + date + 'login' + time + '' # 定義報告文件路徑和名字,路徑為前面定義的path,名字為report(可自定義),格式為.html report_path = path + 'report.html' # 判斷是否定義的路徑目錄存在,不能存在則創建 if not os.path.exists(path): os.makedirs(path) else: pass # 定義一個測試容器 testsuite = unittest.TestSuite() # 將測試用例添加到容器 testsuite.addTest(testLo('test_login')) # 將運行結果保存到report,名字為定義的路徑和文件名,運行腳本 report = open(report_path, ’wb’) #with open(report_path, ’wb’) as report: runner = HTMLTestRunner.HTMLTestRunner(stream=report, title=report_title, description=desc) runner.run(testsuite) # 關閉report,腳本結束 report.close()
csv文件格式:
備注:
使用python處理中文csv文件,并讓execl正確顯示中文(避免亂碼)設施編碼格式為:utf_8_sig,示例:
’’’’’ 將結果導出到result.csv中,以UTF_8 with BOM編碼(微軟產品能正確識別UTF_8 with BOM存儲的中文文件)存儲 ’’’ #data.to_csv(’result_utf8_no_bom.csv’,encoding=’utf_8’)#導出的結果不能別excel正確識別 data.to_csv(’result_utf8_with_bom.csv’,encoding=’utf_8_sig’)
以上這篇python利用Excel讀取和存儲測試數據完成接口自動化教程就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備