輕輕松松吃透Java并發(fā)fork/join框架
Fork / Join 是一個(gè)工具框架 , 其核心思想在于將一個(gè)大運(yùn)算切成多個(gè)小份 , 最大效率的利用資源 , 其主要涉及到三個(gè)類 : ForkJoinPool / ForkJoinTask / RecursiveTask
一、概述java.util.concurrent.ForkJoinPool由Java大師Doug Lea主持編寫,它可以將一個(gè)大的任務(wù)拆分成多個(gè)子任務(wù)進(jìn)行并行處理,最后將子任務(wù)結(jié)果合并成最后的計(jì)算結(jié)果,并進(jìn)行輸出。本文中對(duì)Fork/Join框架的講解,基于JDK1.8+中的Fork/Join框架實(shí)現(xiàn),參考的Fork/Join框架主要源代碼也基于JDK1.8+。
文章將首先先談?wù)剅ecursive task,然后講解Fork/Join框架的基本使用;接著結(jié)合Fork/Join框架的工作原理來理解其中需要注意的使用要點(diǎn);最后再講解使用Fork/Join框架解決一些實(shí)際問題。
二、說一說 RecursiveTaskRecursiveTask 是一種 ForkJoinTask 的遞歸實(shí)現(xiàn) , 例如可以用于計(jì)算斐波那契數(shù)列 :
class Fibonacci extends RecursiveTask<Integer> { final int n; Fibonacci(int n) { this.n = n; } Integer compute() { if (n <= 1) return n; Fibonacci f1 = new Fibonacci(n - 1); f1.fork(); Fibonacci f2 = new Fibonacci(n - 2); return f2.compute() + f1.join(); } }
RecursiveTask 繼承了 ForkJoinTask 接口 ,其內(nèi)部有幾個(gè)主要的方法:
// Node 1 : 返回結(jié)果 , 存放最終結(jié)果V result;// Node 2 : 抽象方法 compute , 用于計(jì)算最終結(jié)果protected abstract V compute();// Node 3 : 獲取最終結(jié)果public final V getRawResult() {return result;}// Node 4 : 最終執(zhí)行方法 , 這里是需要調(diào)用具體實(shí)現(xiàn)類computeprotected final boolean exec() { result = compute(); return true;}
常見使用方式:
@ public class ForkJoinPoolService extends RecursiveTask<Integer> { private static final int THRESHOLD = 2; //閥值 private int start; private int end; public ForkJoinPoolService(Integer start, Integer end) {this.start = start;this.end = end; } @Override protected Integer compute() {int sum = 0;boolean canCompute = (end - start) <= THRESHOLD;if (canCompute) { for (int i = start; i <= end; i++) {sum += i; }} else { int middle = (start + end) / 2; ForkJoinPoolService leftTask = new ForkJoinPoolService(start, middle); ForkJoinPoolService rightTask = new ForkJoinPoolService(middle + 1, end); //執(zhí)行子任務(wù) leftTask.fork(); rightTask.fork(); //等待子任務(wù)執(zhí)行完,并得到其結(jié)果 Integer rightResult = rightTask.join(); Integer leftResult = leftTask.join(); //合并子任務(wù) sum = leftResult + rightResult;}return sum; }}三、 Fork/Join框架基本使用
這里是一個(gè)簡單的Fork/Join框架使用示例,在這個(gè)示例中我們計(jì)算了1-1001累加后的值:
/** * 這是一個(gè)簡單的Join/Fork計(jì)算過程,將1—1001數(shù)字相加 */public class TestForkJoinPool { private static final Integer MAX = 200; static class MyForkJoinTask extends RecursiveTask<Integer> {// 子任務(wù)開始計(jì)算的值private Integer startValue;// 子任務(wù)結(jié)束計(jì)算的值private Integer endValue;public MyForkJoinTask(Integer startValue , Integer endValue) { this.startValue = startValue; this.endValue = endValue;}@Overrideprotected Integer compute() { // 如果條件成立,說明這個(gè)任務(wù)所需要計(jì)算的數(shù)值分為足夠小了 // 可以正式進(jìn)行累加計(jì)算了 if(endValue - startValue < MAX) {System.out.println('開始計(jì)算的部分:startValue = ' + startValue + ';endValue = ' + endValue);Integer totalValue = 0;for(int index = this.startValue ; index <= this.endValue ; index++) { totalValue += index;}return totalValue; } // 否則再進(jìn)行任務(wù)拆分,拆分成兩個(gè)任務(wù) else {MyForkJoinTask subTask1 = new MyForkJoinTask(startValue, (startValue + endValue) / 2);subTask1.fork();MyForkJoinTask subTask2 = new MyForkJoinTask((startValue + endValue) / 2 + 1 , endValue);subTask2.fork();return subTask1.join() + subTask2.join(); }} } public static void main(String[] args) {// 這是Fork/Join框架的線程池ForkJoinPool pool = new ForkJoinPool();ForkJoinTask<Integer> taskFuture = pool.submit(new MyForkJoinTask(1,1001));try { Integer result = taskFuture.get(); System.out.println('result = ' + result);} catch (InterruptedException | ExecutionException e) { e.printStackTrace(System.out);} }}
以上代碼很簡單,在關(guān)鍵的位置有相關(guān)的注釋說明。這里本文再對(duì)以上示例中的要點(diǎn)進(jìn)行說明。首先看看以上示例代碼的可能執(zhí)行結(jié)果:
開始計(jì)算的部分:startValue = 1;endValue = 126開始計(jì)算的部分:startValue = 127;endValue = 251開始計(jì)算的部分:startValue = 252;endValue = 376開始計(jì)算的部分:startValue = 377;endValue = 501開始計(jì)算的部分:startValue = 502;endValue = 626開始計(jì)算的部分:startValue = 627;endValue = 751開始計(jì)算的部分:startValue = 752;endValue = 876開始計(jì)算的部分:startValue = 877;endValue = 1001result = 501501
四、工作順序圖下圖展示了以上代碼的工作過程概要,但實(shí)際上Fork/Join框架的內(nèi)部工作過程要比這張圖復(fù)雜得多,例如如何決定某一個(gè)recursive task是使用哪條線程進(jìn)行運(yùn)行;再例如如何決定當(dāng)一個(gè)任務(wù)/子任務(wù)提交到Fork/Join框架內(nèi)部后,是創(chuàng)建一個(gè)新的線程去運(yùn)行還是讓它進(jìn)行隊(duì)列等待。
所以如果不深入理解Fork/Join框架的運(yùn)行原理,只是根據(jù)之上最簡單的使用例子觀察運(yùn)行效果,那么我們只能知道子任務(wù)在Fork/Join框架中被拆分得足夠小后,并且其內(nèi)部使用多線程并行完成這些小任務(wù)的計(jì)算后再進(jìn)行結(jié)果向上的合并動(dòng)作,最終形成頂層結(jié)果。不急,一步一步來,我們先從這張概要的過程圖開始討論。
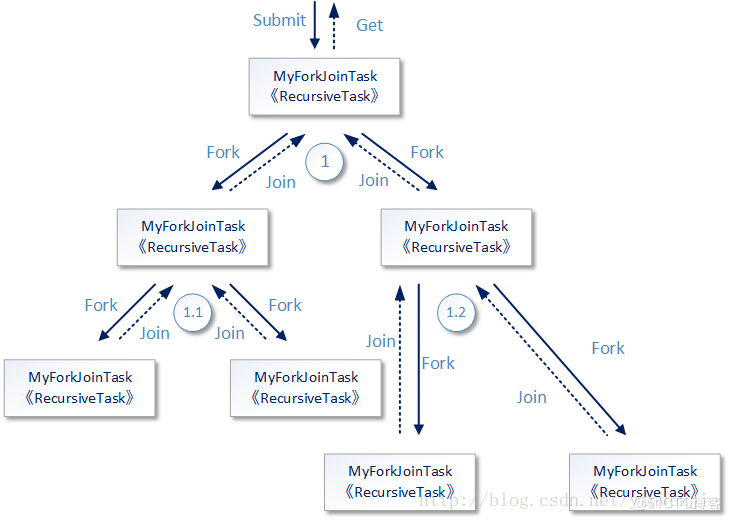
圖中最頂層的任務(wù)使用submit方式被提交到Fork/Join框架中,后者將前者放入到某個(gè)線程中運(yùn)行,工作任務(wù)中的compute方法的代碼開始對(duì)這個(gè)任務(wù)T1進(jìn)行分析。如果當(dāng)前任務(wù)需要累加的數(shù)字范圍過大(代碼中設(shè)定的是大于200),則將這個(gè)計(jì)算任務(wù)拆分成兩個(gè)子任務(wù)(T1.1和T1.2),每個(gè)子任務(wù)各自負(fù)責(zé)計(jì)算一半的數(shù)據(jù)累加,請(qǐng)參見代碼中的fork方法。如果當(dāng)前子任務(wù)中需要累加的數(shù)字范圍足夠小(小于等于200),就進(jìn)行累加然后返回到上層任務(wù)中。
1、ForkJoinPool構(gòu)造函數(shù)ForkJoinPool有四個(gè)構(gòu)造函數(shù),其中參數(shù)最全的那個(gè)構(gòu)造函數(shù)如下所示:
public ForkJoinPool(int parallelism,ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler,boolean asyncMode) parallelism:可并行級(jí)別,F(xiàn)ork/Join框架將依據(jù)這個(gè)并行級(jí)別的設(shè)定,決定框架內(nèi)并行執(zhí)行的線程數(shù)量。并行的每一個(gè)任務(wù)都會(huì)有一個(gè)線程進(jìn)行處理,但是千萬不要將這個(gè)屬性理解成Fork/Join框架中最多存在的線程數(shù)量,也不要將這個(gè)屬性和ThreadPoolExecutor線程池中的corePoolSize、maximumPoolSize屬性進(jìn)行比較,因?yàn)镕orkJoinPool的組織結(jié)構(gòu)和工作方式與后者完全不一樣。而后續(xù)的討論中,讀者還可以發(fā)現(xiàn)Fork/Join框架中可存在的線程數(shù)量和這個(gè)參數(shù)值的關(guān)系并不是絕對(duì)的關(guān)聯(lián)(有依據(jù)但并不全由它決定)。 factory:當(dāng)Fork/Join框架創(chuàng)建一個(gè)新的線程時(shí),同樣會(huì)用到線程創(chuàng)建工廠。只不過這個(gè)線程工廠不再需要實(shí)現(xiàn)ThreadFactory接口,而是需要實(shí)現(xiàn)ForkJoinWorkerThreadFactory接口。后者是一個(gè)函數(shù)式接口,只需要實(shí)現(xiàn)一個(gè)名叫newThread的方法。在Fork/Join框架中有一個(gè)默認(rèn)的ForkJoinWorkerThreadFactory接口實(shí)現(xiàn):DefaultForkJoinWorkerThreadFactory。 handler:異常捕獲處理器。當(dāng)執(zhí)行的任務(wù)中出現(xiàn)異常,并從任務(wù)中被拋出時(shí),就會(huì)被handler捕獲。 asyncMode:這個(gè)參數(shù)也非常重要,從字面意思來看是指的異步模式,它并不是說Fork/Join框架是采用同步模式還是采用異步模式工作。Fork/Join框架中為每一個(gè)獨(dú)立工作的線程準(zhǔn)備了對(duì)應(yīng)的待執(zhí)行任務(wù)隊(duì)列,這個(gè)任務(wù)隊(duì)列是使用數(shù)組進(jìn)行組合的雙向隊(duì)列。即是說存在于隊(duì)列中的待執(zhí)行任務(wù),即可以使用先進(jìn)先出的工作模式,也可以使用后進(jìn)先出的工作模式。
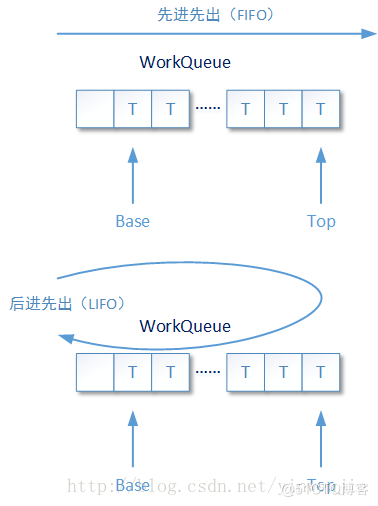
當(dāng)asyncMode設(shè)置為ture的時(shí)候,隊(duì)列采用先進(jìn)先出方式工作;反之則是采用后進(jìn)先出的方式工作,該值默認(rèn)為false
......asyncMode ? FIFO_QUEUE : LIFO_QUEUE,......
ForkJoinPool還有另外兩個(gè)構(gòu)造函數(shù),一個(gè)構(gòu)造函數(shù)只帶有parallelism參數(shù),既是可以設(shè)定Fork/Join框架的最大并行任務(wù)數(shù)量;另一個(gè)構(gòu)造函數(shù)則不帶有任何參數(shù),對(duì)于最大并行任務(wù)數(shù)量也只是一個(gè)默認(rèn)值——當(dāng)前操作系統(tǒng)可以使用的CPU內(nèi)核數(shù)量(Runtime.getRuntime().availableProcessors())。實(shí)際上ForkJoinPool還有一個(gè)私有的、原生構(gòu)造函數(shù),之上提到的三個(gè)構(gòu)造函數(shù)都是對(duì)這個(gè)私有的、原生構(gòu)造函數(shù)的調(diào)用。
......private ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, int mode, String workerNamePrefix) {this.workerNamePrefix = workerNamePrefix;this.factory = factory;this.ueh = handler;this.config = (parallelism & SMASK) | mode;long np = (long)(-parallelism); // offset ctl countsthis.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK); }......
如果你對(duì)Fork/Join框架沒有特定的執(zhí)行要求,可以直接使用不帶有任何參數(shù)的構(gòu)造函數(shù)。也就是說推薦基于當(dāng)前操作系統(tǒng)可以使用的CPU內(nèi)核數(shù)作為Fork/Join框架內(nèi)最大并行任務(wù)數(shù)量,這樣可以保證CPU在處理并行任務(wù)時(shí),盡量少發(fā)生任務(wù)線程間的運(yùn)行狀態(tài)切換(實(shí)際上單個(gè)CPU內(nèi)核上的線程間狀態(tài)切換基本上無法避免,因?yàn)椴僮飨到y(tǒng)同時(shí)運(yùn)行多個(gè)線程和多個(gè)進(jìn)程)。
2、fork方法和join方法Fork/Join框架中提供的fork方法和join方法,可以說是該框架中提供的最重要的兩個(gè)方法,它們和parallelism“可并行任務(wù)數(shù)量”配合工作,可以導(dǎo)致拆分的子任務(wù)T1.1、T1.2甚至TX在Fork/Join框架中不同的運(yùn)行效果。例如TX子任務(wù)或等待其它已存在的線程運(yùn)行關(guān)聯(lián)的子任務(wù),或在運(yùn)行TX的線程中“遞歸”執(zhí)行其它任務(wù),又或者啟動(dòng)一個(gè)新的線程運(yùn)行子任務(wù)……
fork方法用于將新創(chuàng)建的子任務(wù)放入當(dāng)前線程的work queue隊(duì)列中,F(xiàn)ork/Join框架將根據(jù)當(dāng)前正在并發(fā)執(zhí)行ForkJoinTask任務(wù)的ForkJoinWorkerThread線程狀態(tài),決定是讓這個(gè)任務(wù)在隊(duì)列中等待,還是創(chuàng)建一個(gè)新的ForkJoinWorkerThread線程運(yùn)行它,又或者是喚起其它正在等待任務(wù)的ForkJoinWorkerThread線程運(yùn)行它。
這里面有幾個(gè)元素概念需要注意,F(xiàn)orkJoinTask任務(wù)是一種能在Fork/Join框架中運(yùn)行的特定任務(wù),也只有這種類型的任務(wù)可以在Fork/Join框架中被拆分運(yùn)行和合并運(yùn)行。ForkJoinWorkerThread線程是一種在Fork/Join框架中運(yùn)行的特性線程,它除了具有普通線程的特性外,最主要的特點(diǎn)是每一個(gè)ForkJoinWorkerThread線程都具有一個(gè)獨(dú)立的任務(wù)等待隊(duì)列(work queue),這個(gè)任務(wù)隊(duì)列用于存儲(chǔ)在本線程中被拆分的若干子任務(wù)。
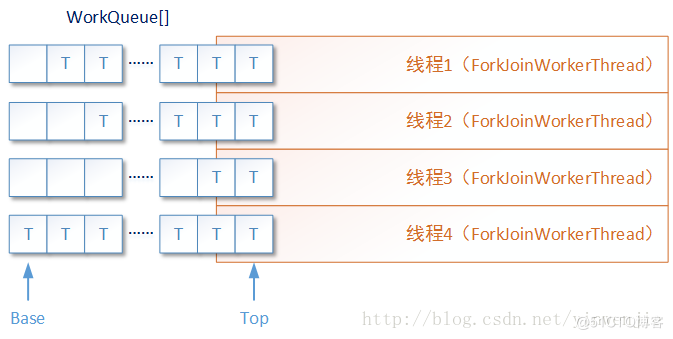
join方法用于讓當(dāng)前線程阻塞,直到對(duì)應(yīng)的子任務(wù)完成運(yùn)行并返回執(zhí)行結(jié)果。或者,如果這個(gè)子任務(wù)存在于當(dāng)前線程的任務(wù)等待隊(duì)列(work queue)中,則取出這個(gè)子任務(wù)進(jìn)行“遞歸”執(zhí)行。其目的是盡快得到當(dāng)前子任務(wù)的運(yùn)行結(jié)果,然后繼續(xù)執(zhí)行。
五、使用Fork/Join解決實(shí)際問題之前所舉的的例子是使用Fork/Join框架完成1-1000的整數(shù)累加。這個(gè)示例如果只是演示Fork/Join框架的使用,那還行,但這種例子和實(shí)際工作中所面對(duì)的問題還有一定差距。本篇文章我們使用Fork/Join框架解決一個(gè)實(shí)際問題,就是高效排序的問題。
1.使用歸并算法解決排序問題排序問題是我們工作中的常見問題。目前也有很多現(xiàn)成算法是為了解決這個(gè)問題而被發(fā)明的,例如多種插值排序算法、多種交換排序算法。而并歸排序算法是目前所有排序算法中,平均時(shí)間復(fù)雜度較好(O(nlgn)),算法穩(wěn)定性較好的一種排序算法。它的核心算法思路將大的問題分解成多個(gè)小問題,并將結(jié)果進(jìn)行合并。
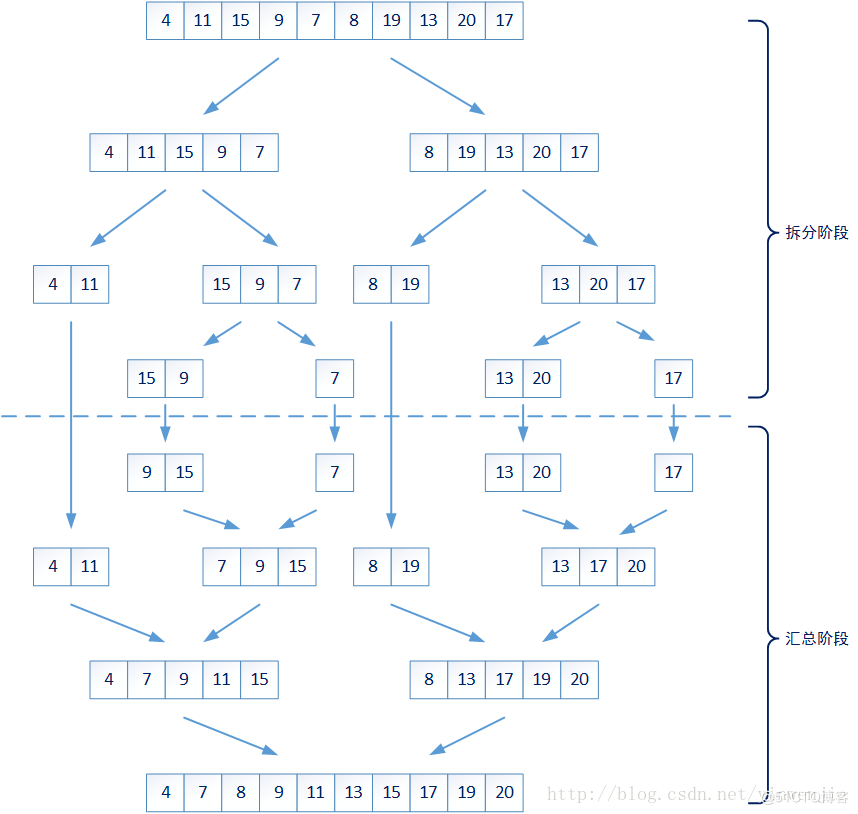
整個(gè)算法的拆分階段,是將未排序的數(shù)字集合,從一個(gè)較大集合遞歸拆分成若干較小的集合,這些較小的集合要么包含最多兩個(gè)元素,要么就認(rèn)為不夠小需要繼續(xù)進(jìn)行拆分。
那么對(duì)于一個(gè)集合中元素的排序問題就變成了兩個(gè)問題:1、較小集合中最多兩個(gè)元素的大小排序;2、如何將兩個(gè)有序集合合并成一個(gè)新的有序集合。第一個(gè)問題很好解決,那么第二個(gè)問題是否會(huì)很復(fù)雜呢?實(shí)際上第二個(gè)問題也很簡單,只需要將兩個(gè)集合同時(shí)進(jìn)行一次遍歷即可完成——比較當(dāng)前集合中最小的元素,將最小元素放入新的集合,它的時(shí)間復(fù)雜度為O(n):
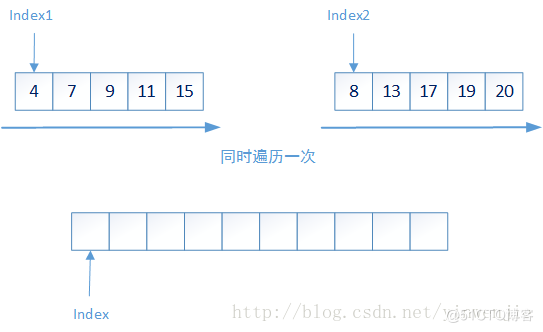
以下是歸并排序算法的簡單實(shí)現(xiàn):
package test.thread.pool.merge;import java.util.Arrays;import java.util.Random;/** * 歸并排序 * @author yinwenjie */public class Merge1 { private static int MAX = 10000; private static int inits[] = new int[MAX]; // 這是為了生成一個(gè)數(shù)量為MAX的隨機(jī)整數(shù)集合,準(zhǔn)備計(jì)算數(shù)據(jù) // 和算法本身并沒有什么關(guān)系 static {Random r = new Random();for(int index = 1 ; index <= MAX ; index++) { inits[index - 1] = r.nextInt(10000000);} } public static void main(String[] args) {long beginTime = System.currentTimeMillis();int results[] = forkits(inits); long endTime = System.currentTimeMillis();// 如果參與排序的數(shù)據(jù)非常龐大,記得把這種打印方式去掉System.out.println('耗時(shí)=' + (endTime - beginTime) + ' | ' + Arrays.toString(results)); } // 拆分成較小的元素或者進(jìn)行足夠小的元素集合的排序 private static int[] forkits(int source[]) {int sourceLen = source.length;if(sourceLen > 2) { int midIndex = sourceLen / 2; int result1[] = forkits(Arrays.copyOf(source, midIndex)); int result2[] = forkits(Arrays.copyOfRange(source, midIndex , sourceLen)); // 將兩個(gè)有序的數(shù)組,合并成一個(gè)有序的數(shù)組 int mer[] = joinInts(result1 , result2); return mer;} // 否則說明集合中只有一個(gè)或者兩個(gè)元素,可以進(jìn)行這兩個(gè)元素的比較排序了else { // 如果條件成立,說明數(shù)組中只有一個(gè)元素,或者是數(shù)組中的元素都已經(jīng)排列好位置了 if(sourceLen == 1|| source[0] <= source[1]) {return source; } else {int targetp[] = new int[sourceLen];targetp[0] = source[1];targetp[1] = source[0];return targetp; }} } /** * 這個(gè)方法用于合并兩個(gè)有序集合 * @param array1 * @param array2 */ private static int[] joinInts(int array1[] , int array2[]) {int destInts[] = new int[array1.length + array2.length];int array1Len = array1.length;int array2Len = array2.length;int destLen = destInts.length;// 只需要以新的集合destInts的長度為標(biāo)準(zhǔn),遍歷一次即可for(int index = 0 , array1Index = 0 , array2Index = 0 ; index < destLen ; index++) { int value1 = array1Index >= array1Len?Integer.MAX_VALUE:array1[array1Index]; int value2 = array2Index >= array2Len?Integer.MAX_VALUE:array2[array2Index]; // 如果條件成立,說明應(yīng)該取數(shù)組array1中的值 if(value1 < value2) {array1Index++;destInts[index] = value1; } // 否則取數(shù)組array2中的值 else {array2Index++;destInts[index] = value2; }}return destInts; }}
以上歸并算法對(duì)1萬條隨機(jī)數(shù)進(jìn)行排序只需要2-3毫秒,對(duì)10萬條隨機(jī)數(shù)進(jìn)行排序只需要20毫秒左右的時(shí)間,對(duì)100萬條隨機(jī)數(shù)進(jìn)行排序的平均時(shí)間大約為160毫秒(這還要看隨機(jī)生成的待排序數(shù)組是否本身的凌亂程度)。可見歸并算法本身是具有良好的性能的。使用JMX工具和操作系統(tǒng)自帶的CPU監(jiān)控器監(jiān)視應(yīng)用程序的執(zhí)行情況,可以發(fā)現(xiàn)整個(gè)算法是單線程運(yùn)行的,且同一時(shí)間CPU只有單個(gè)內(nèi)核在作為主要的處理內(nèi)核工作:
JMX中觀察到的線程情況:
CPU的運(yùn)作情況:
但是隨著待排序集合中數(shù)據(jù)規(guī)模繼續(xù)增大,以上歸并算法的代碼實(shí)現(xiàn)就有一些力不從心了,例如以上算法對(duì)1億條隨機(jī)數(shù)集合進(jìn)行排序時(shí),耗時(shí)為27秒左右。
接著我們可以使用Fork/Join框架來優(yōu)化歸并算法的執(zhí)行性能,將拆分后的子任務(wù)實(shí)例化成多個(gè)ForkJoinTask任務(wù)放入待執(zhí)行隊(duì)列,并由Fork/Join框架在多個(gè)ForkJoinWorkerThread線程間調(diào)度這些任務(wù)。如下圖所示:
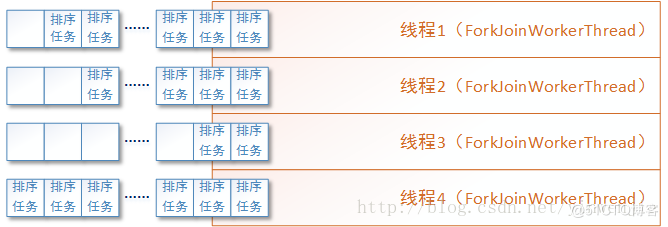
以下為使用Fork/Join框架后的歸并算法代碼,請(qǐng)注意joinInts方法中對(duì)兩個(gè)有序集合合并成一個(gè)新的有序集合的代碼,是沒有變化的可以參見本文上一小節(jié)中的內(nèi)容。所以在代碼中就不再贅述了:
....../** * 使用Fork/Join框架的歸并排序算法 * @author yinwenjie */public class Merge2 { private static int MAX = 100000000; private static int inits[] = new int[MAX]; // 同樣進(jìn)行隨機(jī)隊(duì)列初始化,這里就不再贅述了 static {...... } public static void main(String[] args) throws Exception { // 正式開始long beginTime = System.currentTimeMillis();ForkJoinPool pool = new ForkJoinPool();MyTask task = new MyTask(inits);ForkJoinTask<int[]> taskResult = pool.submit(task);try { taskResult.get();} catch (InterruptedException | ExecutionException e) { e.printStackTrace(System.out);}long endTime = System.currentTimeMillis();System.out.println('耗時(shí)=' + (endTime - beginTime)); } /** * 單個(gè)排序的子任務(wù) * @author yinwenjie */ static class MyTask extends RecursiveTask<int[]> {private int source[];public MyTask(int source[]) { this.source = source;}/* (non-Javadoc) * @see java.util.concurrent.RecursiveTask#compute() */@Overrideprotected int[] compute() { int sourceLen = source.length; // 如果條件成立,說明任務(wù)中要進(jìn)行排序的集合還不夠小 if(sourceLen > 2) {int midIndex = sourceLen / 2;// 拆分成兩個(gè)子任務(wù)MyTask task1 = new MyTask(Arrays.copyOf(source, midIndex));task1.fork();MyTask task2 = new MyTask(Arrays.copyOfRange(source, midIndex , sourceLen));task2.fork();// 將兩個(gè)有序的數(shù)組,合并成一個(gè)有序的數(shù)組int result1[] = task1.join();int result2[] = task2.join();int mer[] = joinInts(result1 , result2);return mer; } // 否則說明集合中只有一個(gè)或者兩個(gè)元素,可以進(jìn)行這兩個(gè)元素的比較排序了 else {// 如果條件成立,說明數(shù)組中只有一個(gè)元素,或者是數(shù)組中的元素都已經(jīng)排列好位置了if(sourceLen == 1 || source[0] <= source[1]) { return source;} else { int targetp[] = new int[sourceLen]; targetp[0] = source[1]; targetp[1] = source[0]; return targetp;} }}private int[] joinInts(int array1[] , int array2[]) { // 和上文中出現(xiàn)的代碼一致} }}
使用Fork/Join框架優(yōu)化后,同樣執(zhí)行1億條隨機(jī)數(shù)的排序處理時(shí)間大約在14秒左右,當(dāng)然這還和待排序集合本身的凌亂程度、CPU性能等有關(guān)系。但總體上這樣的方式比不使用Fork/Join框架的歸并排序算法在性能上有30%左右的性能提升。以下為執(zhí)行時(shí)觀察到的CPU狀態(tài)和線程狀態(tài):
JMX中的內(nèi)存、線程狀態(tài):
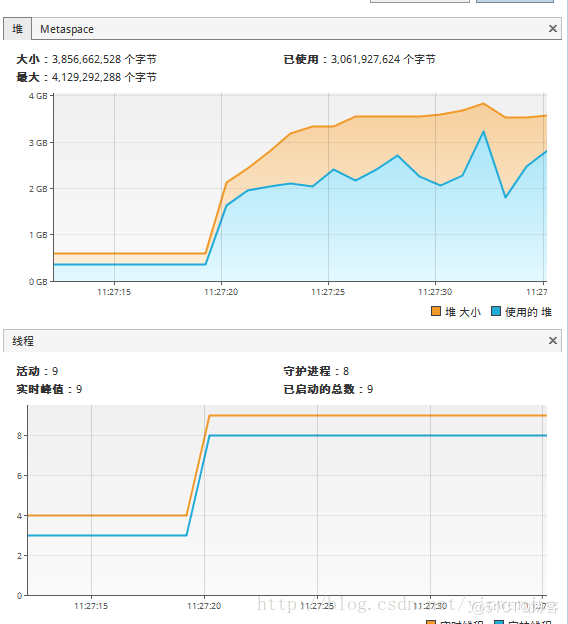
CPU使用情況:
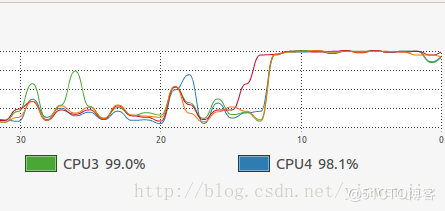
除了歸并算法代碼實(shí)現(xiàn)內(nèi)部可優(yōu)化的細(xì)節(jié)處,使用Fork/Join框架后,我們基本上在保證操作系統(tǒng)線程規(guī)模的情況下,將每一個(gè)CPU內(nèi)核的運(yùn)算資源同時(shí)發(fā)揮了出來。
到此這篇關(guān)于輕輕松松吃透Java并發(fā)fork/join框架的文章就介紹到這了,更多相關(guān)Java fork/join框架內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. phpstudy apache開啟ssi使用詳解2. .Net加密神器Eazfuscator.NET?2023.2?最新版使用教程3. JSP之表單提交get和post的區(qū)別詳解及實(shí)例4. Xml簡介_動(dòng)力節(jié)點(diǎn)Java學(xué)院整理5. 詳解瀏覽器的緩存機(jī)制6. jsp文件下載功能實(shí)現(xiàn)代碼7. 如何在jsp界面中插入圖片8. ASP動(dòng)態(tài)網(wǎng)頁制作技術(shù)經(jīng)驗(yàn)分享9. jsp實(shí)現(xiàn)登錄驗(yàn)證的過濾器10. .Net Core和RabbitMQ限制循環(huán)消費(fèi)的方法

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備