分布式爬蟲 - scrapy-redis 分布式系統?
問題描述
現在可以從網上下載這些代碼,怎么進行部署和運行代碼從github上下載了關于分布式的代碼,不知道怎么用,求各位大神指點下。。。下面是網址https://github.com/rolando/scrapy-redis環境已經按照上面的配置好了,但不知道如何實現分布式。分布式我是這樣理解的,有一個redis服務器,從一個網頁上獲取url種子,并將url種子放到redis服務器了,然后將這些url種子分配給其他機器。中間存在調度方面的問題,以及服務器和機器間的通信。
謝謝。。。
問題解答
回答1:感覺這個不是一兩句話可以描述清楚 的。
我之前參考的這篇博文,希望對你有幫助。
說說我個人的理解吧。
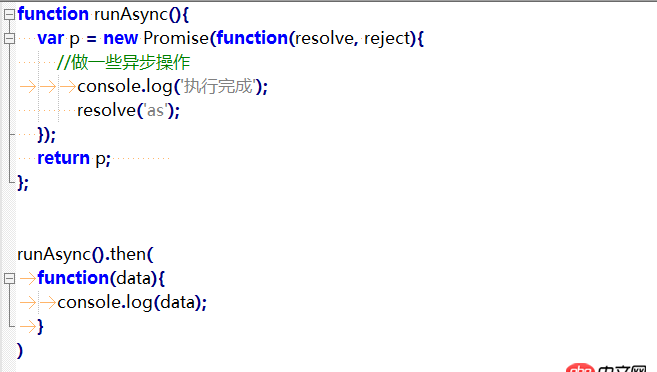
scrapy使用改良之后的python自帶的collection.deque來存放待爬取的request,該怎么讓兩個以上的Spider共用這個deque呢?
待爬隊列都不能共享,分布式就是無稽之談。scrapy-redis提供了一個解決方法,把collection.deque換成redis數據庫,多個爬蟲從同一個redis服務器存放要爬取的request,這樣就能讓多個spider去同一個數據庫里讀取,這樣分布式的主要問題就解決了.
注意:并不是換了redis來存放request,scrapy就能直接分布式了!
scrapy中跟待爬隊列直接相關的就是調度器Scheduler。
參考scrapy的結構
它負責對新的request進行入列操作,取出下一個要爬取的request等操作。所以,換了redis之后,其他組件都要改動。
所以,我個人的理解就是,在多個機器上部署相同的爬蟲,分布式部署redis,參考地址我的博客,比較簡單。而這些工作,包括url去重,就是已經寫好的scrapy-redis框架的功能。
參考地址在這里,你可以去下載example看看具體的實現。我最近也在搞這個scrapy-redis,等我部署好了在更新的這個答案。
你有新的進展可以分享出來交流。
回答2:@韋軒 您好,我看這段評論在15.10.11,請問您現在是否有結果了?能否推薦一些您的博客,謝謝您~可以聯系我[email protected]
相關文章:
1. javascript - node.js promise沒用2. node.js - nodejs如何發送請求excel文件并下載3. 為什么我ping不通我的docker容器呢???4. 算法 - python 給定一個正整數a和一個包含任意個正整數的 列表 b,求所有<=a 的加法組合5. android 如何實現如圖中的鍵盤上的公式及edittext的內容展示呢6. golang - 用IDE看docker源碼時的小問題7. java - 我在用Struts2上傳文件時,報以下錯誤怎么回事?8. PHP注冊功能9. MySQL如何實現表中再嵌套一個表?10. mysql - 求SQL語句
 網公網安備
網公網安備