文章詳情頁
python - 基于scrapy-redis的分布式爬蟲運行的時候不能正常運行 遇到的問題如下截圖所示
瀏覽:97日期:2022-08-03 11:20:00
問題描述
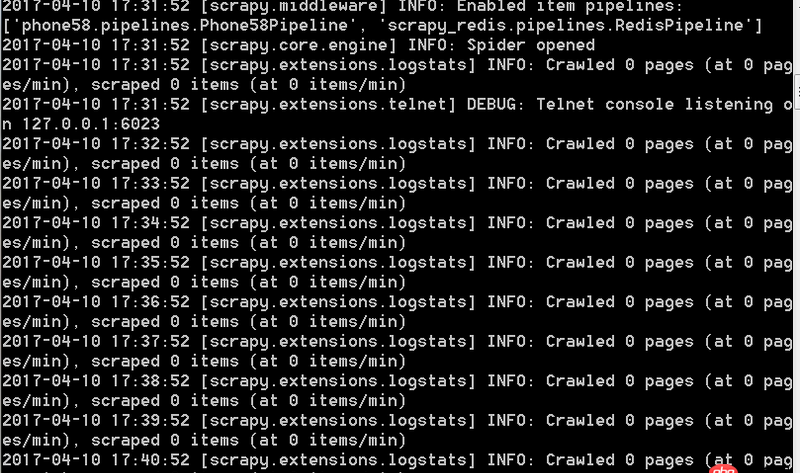
爬蟲運行時一直是這樣的每一分鐘出現一條這樣的信息,無限循環。不能爬取下來數據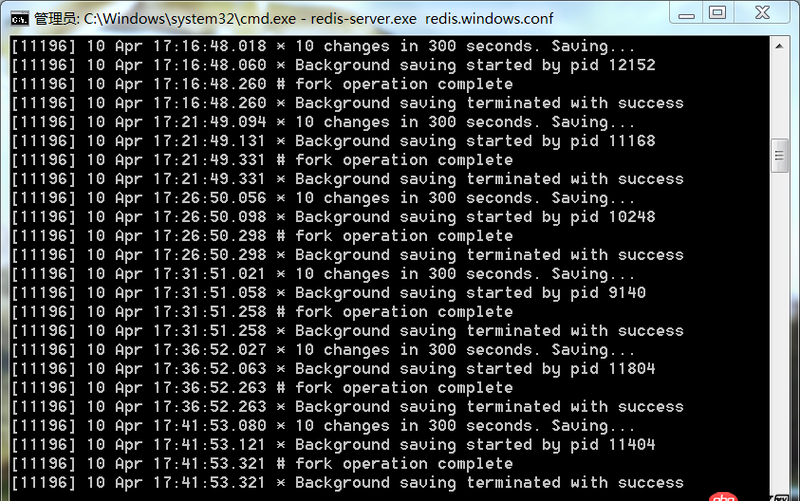
這是redis服務端的顯示
這樣是什么問題,望有高手可以為我解惑,謝謝。
問題解答
回答1:使用scrapy_redis,你要去投放url讓spider去爬取,你投放了嗎?比如
redis-cli lpush myspider:start_urls http://google.com
相關文章:
1. java - mongodb分片集群下,count和聚合統計問題2. javascript - vue 移動端的input 數字輸入優化3. java - 自己制作一個視頻播放器,遇到問題,用的是內置surfaceview類,具體看代碼!4. javascript - 有什么兼容性比較好的辦法來判斷瀏覽器窗口的類型?5. 服務器端 - 采用nginx做web服務器,C++開發應用程序 出現拒絕連接請求?6. 為什么我ping不通我的docker容器呢???7. python - pandas按照列A和列B分組,將列C求平均數,怎樣才能生成一個列A,B,C的dataframe8. 關于docker下的nginx壓力測試9. javascript - npm start 運行’webpack-dev-server’報錯 Cannot find module ’webpack’10. java 隨機延遲執行
排行榜

 網公網安備
網公網安備