文章詳情頁
網頁爬蟲 - Python:爬蟲的中文編碼問題?
瀏覽:127日期:2022-08-26 10:56:16
問題描述
爬取中文網頁后正則匹配出中文,得打UTF-8的編碼字符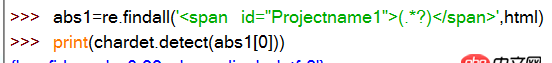
將其輸出為.csv文件
在.CSV中顯示為亂碼
用記事本打開.csv又可以正常顯示為中文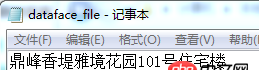
有沒有大神指點是怎么一回事?怎樣才能在Excel里直接看到中文?
問題解答
回答1:簡單地方法是用pandas的to_excel方法轉化成.xlsx文件,因為.xlsx默認編碼是默認支持Excel的,區別當然是無法用記事本打開。
import pandas as pda = pd.read_csv(’./test.csv’)a.to_excel(’./test_output.xlsx’, index=False)a.to_excel(’./test_output.csv’, index=False)
我這里沒有windows可以測試,可以嘗試寫入編碼為gb2312或者gbk試試。
表格文件類I/O的話其實pandas更方便一點。
回答2:abs1=abs1.decode().encode(’gbk’)
回答3:excel默認使用的是GBK編碼。
回答4:新建一個excel文件,然后點 數據 自文本,導入csv文件
相關文章:
1. linux - Ubuntu下編譯Vim8(+python)無數次編譯失敗2. javascript - 靜態頁面html 引頭尾公共文件?3. javascript - vscode alt+shift+f 格式化js代碼,通不過eslint的代碼風格檢查怎么辦。。。4. css - linear-gradient無效是怎么回事?5. python中怎么對列表以區間進行統計?6. javascript - 如何判斷用戶切換到了當前標簽頁?7. javascript - react 里使用antd model 怎么控制model 開關8. javascript - 寫移動端的頁面的時候,有不一快空白,是怎么回事?9. javascript - webpack 報錯 新人 求解10. css - 移動端 盒子內加overflow-y:scroll后 字體會變大
排行榜
 網公網安備
網公網安備