文章詳情頁
網頁爬蟲 - Python爬蟲返回狀態碼與實際情況不符?
瀏覽:163日期:2022-09-03 18:57:11
問題描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態碼是200。
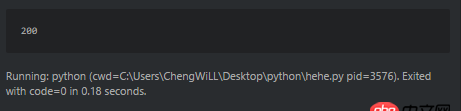
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應的也是404,請問這是為什么?
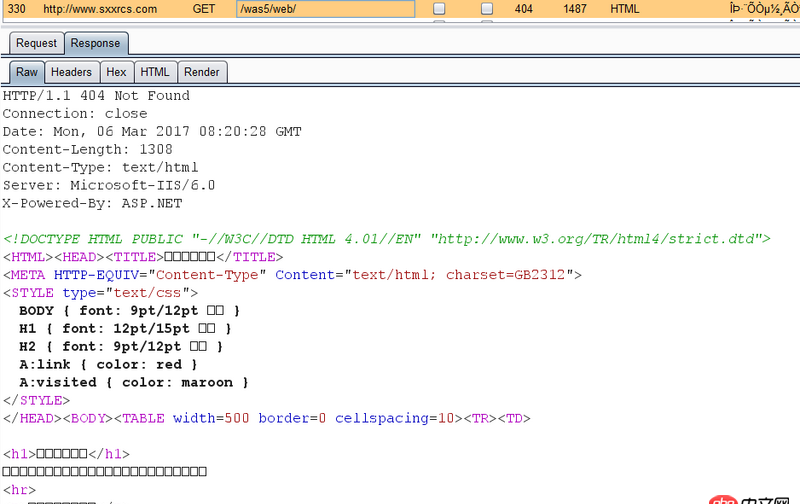
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關文章:
1. android - NavigationView 的側滑菜單中如何保存新增項(通過程序添加)2. jquery清除input type為password?3. python-mysqldb - 這樣結構的mysql表,如何快速update4. 這段代碼既不提示錯誤也看不到結果,請老師明示錯在哪里,謝謝!5. php7.3.4中怎么開啟pdo驅動6. 微信小程序可以用gulp,webpack嗎?7. 老師 我是一個沒有學過php語言的準畢業生 我希望您能幫我一下8. ueditor上傳服務器提示后端配置項沒有正常加載,求助!!!!!9. 提示語法錯誤語法錯誤: unexpected ’abstract’ (T_ABSTRACT)10. tp5 不同控制器中的變量調用問題
排行榜
 網公網安備
網公網安備