文章詳情頁
java中這個頁面默認(rèn)是utf-8編碼的,1輸出亂碼可以理解,可是2就不理解了?
瀏覽:112日期:2024-01-18 13:07:46
問題描述
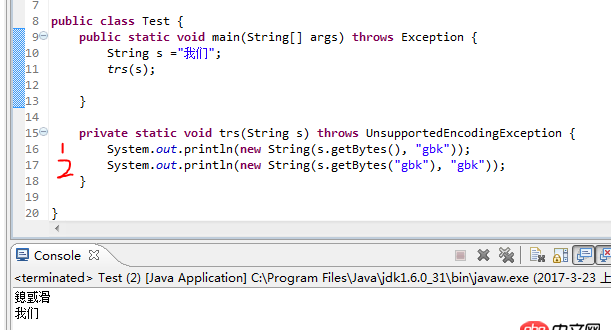
s按照gbk解碼,在按照gbk組合成String,為什么就不是亂碼了呢? 那2這個字符串是最終是什么編碼 utf-8還是gbk
問題解答
回答1:1:s.getBytes()不帶參數(shù)的話會調(diào)用jdk默認(rèn)的編碼(你的可能是utf-8)將字符串解碼成byte[],然后你使用gbk的編碼方式重新將byte[]編碼成字符串,所以會出現(xiàn)亂碼。
2.s.getBytes(’gbk’)你將字符串按照gbk的方式解碼后又重新使用gbk方式編碼,所以不會出現(xiàn)亂碼。
回答2:樓上說的沒錯,補充一點jdk的默認(rèn)編碼是file.encoding中指定的編碼,可以通過Dfile.encoding=GBK這樣來修改JVM的默認(rèn)編碼。
再補充一點編解碼的知識,“你好”這個中文要在計算機中傳輸,必然要把它轉(zhuǎn)換為2進(jìn)制。怎么轉(zhuǎn)二進(jìn)制就是這里說的解碼。編碼的方式有很多種,比如Unicode字符集。這個字符集里面就是各種符號對應(yīng)的數(shù)字,比如你用2345來表示,然后按照一定的方式轉(zhuǎn)換的二進(jìn)制(具體怎么轉(zhuǎn)換可以網(wǎng)上找一下具體過程)。接收到這一串二進(jìn)制數(shù),怎么轉(zhuǎn)為漢字就是這里說的編碼。編碼需要按照一定的方式去解才能得到正確的字符對應(yīng)關(guān)系,比如你的二進(jìn)制為0101010010,需要按照utf-8的方式去編碼才能得到你這個符號并顯示出來。
標(biāo)簽:
java
排行榜

熱門標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備