Python爬蟲爬取博客實(shí)現(xiàn)可視化過程解析
源碼:
from pyecharts import Barimport reimport requestsnum=0b=[]for i in range(1,11): link=’https://www.cnblogs.com/echoDetected/default.html?page=’+str(i) headers={’user-agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36’} r=requests.get(link,headers=headers) html=r.text post=re.findall(’<span class='post-view-count'>(.*?)</span>’,html)for i in post: i = i.replace('閱讀(', '') i = i.replace(')','') b.append(i) num=num+1columns=[]for i in range(1,num+1):#設(shè)置行名 columns.append(’博客’+str(i))#設(shè)置數(shù)據(jù)#設(shè)置柱狀圖的主標(biāo)題與副標(biāo)題bar = Bar('柱狀圖', '每個(gè)博客閱讀數(shù)量')#添加柱狀圖的數(shù)據(jù)及配置項(xiàng),先行后列bar.add('閱讀量', columns, b, mark_line=['average'], mark_point=['max', 'min'])#生成本地文件(默認(rèn)為.html文件)bar.render()
爬蟲不是重點(diǎn),只是拿來爬閱讀數(shù)量,pyecharts是重點(diǎn)
這次爬的是我自己的博客,一共10頁,每頁10片文章,正好寫了100篇博客
pyecharts安裝:
pip install wheelpip install pyecharts==0.1.9.4
直接pip install pyecharts會(huì)下載最新版無法調(diào)用
注意點(diǎn):pyecharts調(diào)用,貌似無法實(shí)現(xiàn)多個(gè)py文件一起調(diào)用(意思是編寫時(shí)不能在多個(gè)文件里出現(xiàn)import語句)
步驟解釋:
1.爬蟲爬取閱讀數(shù)
2.去除非法字符裝入新的數(shù)組
3.設(shè)置橫軸數(shù)據(jù),生成柱狀圖
4.在當(dāng)前目錄下生成render.html,打開查看柱狀圖
結(jié)果:
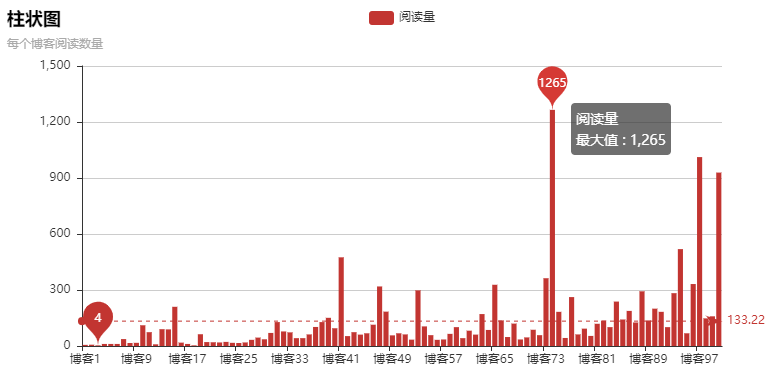
柱狀圖是動(dòng)態(tài)的,不是靜態(tài)的
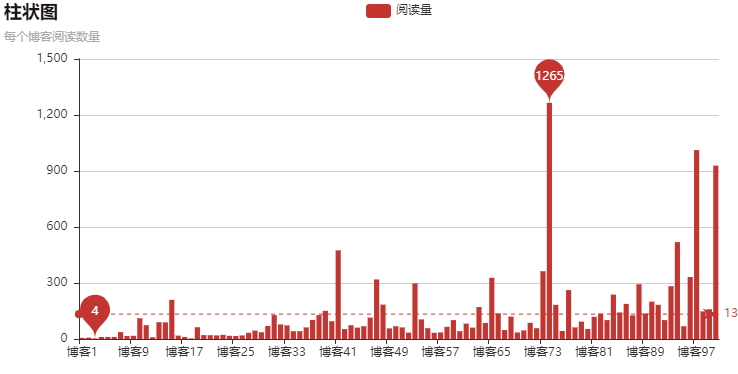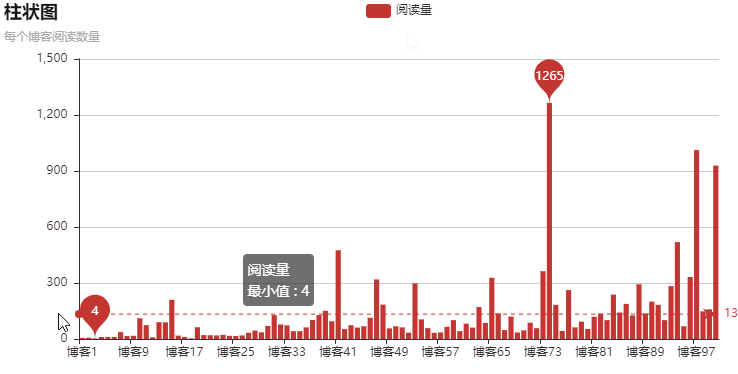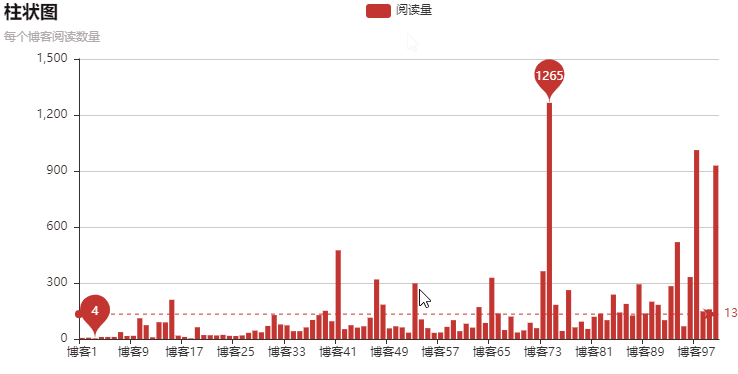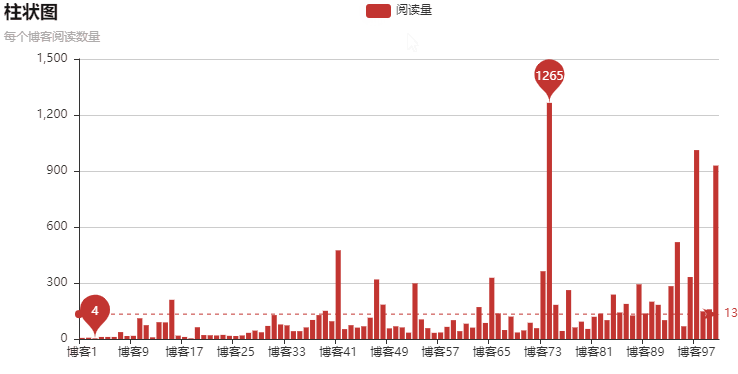
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. Python如何批量生成和調(diào)用變量2. ASP.Net Core對USB攝像頭進(jìn)行截圖3. ASP.NET MVC實(shí)現(xiàn)橫向展示購物車4. Python 中如何使用 virtualenv 管理虛擬環(huán)境5. Python獲取B站粉絲數(shù)的示例代碼6. Python基于requests實(shí)現(xiàn)模擬上傳文件7. python利用opencv實(shí)現(xiàn)顏色檢測8. windows服務(wù)器使用IIS時(shí)thinkphp搜索中文無效問題9. ASP.Net Core(C#)創(chuàng)建Web站點(diǎn)的實(shí)現(xiàn)10. 通過CSS數(shù)學(xué)函數(shù)實(shí)現(xiàn)動(dòng)畫特效

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備