python隨機(jī)模塊random的22種函數(shù)(小結(jié))
前言
隨機(jī)數(shù)可以用于數(shù)學(xué),游戲,安全等領(lǐng)域中,還經(jīng)常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。平時(shí)數(shù)據(jù)分析各種分布的數(shù)據(jù)構(gòu)造也會(huì)用到。
random模塊,用于生成偽隨機(jī)數(shù),之所以稱(chēng)之為偽隨機(jī)數(shù),是因?yàn)檎嬲饬x上的隨機(jī)數(shù)(或者隨機(jī)事件)在某次產(chǎn)生過(guò)程中是按照實(shí)驗(yàn)過(guò)程中表現(xiàn)的分布概率隨機(jī)產(chǎn)生的,其結(jié)果是不可預(yù)測(cè)的,是不可見(jiàn)的。而計(jì)算機(jī)中的隨機(jī)函數(shù)是按照一定算法模擬產(chǎn)生的,對(duì)于正常隨機(jī)而言,會(huì)出現(xiàn)某個(gè)事情出現(xiàn)多次的情況。
但是偽隨機(jī)在事情觸發(fā)前設(shè)定好,就是這個(gè)十個(gè)事件各發(fā)生一次,只不過(guò)順序不同而已。現(xiàn)在MP3的隨機(jī)列表就是用的偽隨機(jī),把要播放的歌曲打亂順序,生成一個(gè)隨機(jī)列表而已,每個(gè)歌曲都播放一次。真實(shí)隨機(jī)的話(huà),會(huì)有出現(xiàn)某首歌多放次的情況,歌曲基數(shù)越多,重放的概率越大。
注意:random()是不能直接訪(fǎng)問(wèn)的,需要導(dǎo)入 random 模塊,然后通過(guò) random 靜態(tài)對(duì)象調(diào)用該方法。
import randomlist(dir(random))[’BPF’, ’LOG4’,’NV_MAGICCONST’,’RECIP_BPF’,’Random’,’SG_MAGICCONST’,’SystemRandom’,’TWOPI’,’betavariate’,’choice’,’choices’,’expovariate’,’gammavariate’,’gauss’,’getrandbits’,’getstate’,’lognormvariate’,’normalvariate’,’paretovariate’,’randint’,’random’,’randrange’,’sample’,’seed’,’setstate’,’shuffle’,’triangular’,’uniform’,’vonmisesvariate’,’weibullvariate’]#加載所需要的包import randomimport matplotlib.pyplot as pltimport seaborn as sns
random.random()
描述:random.random() 用于生成一個(gè)0到1的隨機(jī)符點(diǎn)數(shù): 0 <= n < 1.0語(yǔ)法:random.random()
#生成一個(gè)隨機(jī)數(shù)random.random()0.7186311708109537#生成一個(gè)4位小數(shù)的隨機(jī)列表[round(random.random(),4) for i in range(10)][0.1693, 0.4698, 0.5849, 0.6859, 0.2818, 0.216, 0.1976, 0.3171, 0.2522, 0.8012]#生成一串隨機(jī)數(shù)for i in range(10):print(random.random())0.43860556392473480.43944378539770780.2318629636828330.64831689635533420.121065812558118550.70438749865313550.387295196584986230.64922561571703930.4634250509335640.2298431522075462
random.choice()
描述:從非空序列seq中隨機(jī)選取一個(gè)元素。如果seq為空則彈出 IndexError異常。語(yǔ)法:random.choice( seq)seq 可以是一個(gè)列表,元組或字符串。
L = [0,1,2,3,4,5]random.choice(L)2L = ’wofeichangshuai’random.choice(L)’h’
random.choices()
描述:從集群中隨機(jī)選取k次數(shù)據(jù),返回一個(gè)列表,可以設(shè)置權(quán)重。注意每次選取都不會(huì)影響原序列,每一次選取都是基于原序列。也就是有放回抽樣語(yǔ)法:random.choices(population,weights=None,*,cum_weights=None,k=1)參數(shù):
population:集群。 weights:相對(duì)權(quán)重。 cum_weights:累加權(quán)重。 k:選取次數(shù)。a = [1,2,3,4,5]random.choices(a,k=5)[2, 5, 2, 1, 3]random.choices(a,weights=[0,0,1,0,0],k=5)[3, 3, 3, 3, 3]random.choices(a,weights=[1,1,1,1,1],k=5)[3, 1, 5, 2, 2]#多次運(yùn)行,5被抽到的概率為0.5,比其他的都大random.choices(a,weights=[0.1,0.1,0.2,0.3,0.5],k=5)[5, 4, 4, 4, 2]random.choices(a,weights=[0.1,0.1,0.2,0.3,0.5],k=5)[5, 4, 5, 5, 2]random.choices(a,weights=[0.1,0.1,0.2,0.3,0.5],k=5)[5, 2, 2, 5, 5]random.choices(a,cum_weights=[1,1,1,1,1],k=5)[1, 1, 1, 1, 1]
對(duì)每一條語(yǔ)句不妨各自寫(xiě)一個(gè)循環(huán)語(yǔ)句讓它輸出個(gè)十遍八遍的,你就足以看出用法了。
結(jié)論:參數(shù)weights設(shè)置相對(duì)權(quán)重,它的值是一個(gè)列表,設(shè)置之后,每一個(gè)成員被抽取到的概率就被確定了。比如weights=[1,2,3,4,5],那么第一個(gè)成員的概率就是P=1/(1+2+3+4+5)=1/15。cum_weights設(shè)置累加權(quán)重,Python會(huì)自動(dòng)把相對(duì)權(quán)重轉(zhuǎn)換為累加權(quán)重,即如果你直接給出累加權(quán)重,那么就不需要給出相對(duì)權(quán)重,且Python省略了一步執(zhí)行。比如weights=[1,2,3,4],那么cum_weights=[1,3,6,10],這也就不難理解為什么cum_weights=[1,1,1,1,1]輸出全是第一
random.getrandbits()
描述:返回一個(gè)不大于K位的Python整數(shù)(十進(jìn)制),比如k=10,則結(jié)果在0~2^10之間的整數(shù)。語(yǔ)法:random.getrandbits(k)
random.getrandbits(10)379
random.getstate()
描述:返回一個(gè)捕獲到的 生成器當(dāng)前內(nèi)部狀態(tài) 的對(duì)象,可以將此對(duì)象傳遞給 setstate() 以恢復(fù)到這個(gè)狀態(tài)。語(yǔ)法:random.getstate()
random.setstate()
描述:state 應(yīng)該是從之前調(diào)用 getstate() 獲得的,而 setstate() 將生成器的內(nèi)部狀態(tài)恢復(fù)到調(diào)用 getstate() 時(shí)的狀態(tài)。根據(jù)下面的例子可以看出,由于生成器內(nèi)部狀態(tài)相同時(shí)會(huì)生成相同的下一個(gè)隨機(jī)數(shù),我們可以使用 getstate() 和 setstate() 對(duì)生成器內(nèi)部狀態(tài)進(jìn)行獲取和重置到某一狀態(tài)下。語(yǔ)法:random.setstate(state)
state = random.getstate()random.random()0.489148634943random.random()0.22359638172661822random.setstate(state)random.random()0.48914863494
random.randint()
描述:用于生成一個(gè)指定范圍內(nèi)的整數(shù)。語(yǔ)法:random.randint(a, b),其中參數(shù)a是下限,參數(shù)b是上限,生成的隨機(jī)數(shù)n: a <= n <= b
random.randint(1, 8)3random.randint(1, 8)4
random.randrange()
描述:按指定基數(shù)遞增的集合中 獲取一個(gè)隨機(jī)數(shù)。如:random.randrange(10, 100, 2),結(jié)果相當(dāng)于從[10, 12, 14, 16, … 96, 98]序列中獲取一個(gè)隨機(jī)數(shù),random.randrange(10, 100, 2)在結(jié)果上與 random.choice(range(10, 100, 2) 等效。語(yǔ)法:random.randrange([start], stop[, step])
不指定step,隨機(jī)生成[a,b)范圍內(nèi)一個(gè)整數(shù)。 指定step,step作為步長(zhǎng)會(huì)進(jìn)一步限制[a,b)的范圍,比如randrange(0,11,2)意即生成[0,11)范圍內(nèi)的隨機(jī)偶數(shù)。 不指定a,則默認(rèn)從0開(kāi)始。#不限制[random.randrange(0,11) for i in range(5)][4, 6, 3, 9, 5]#隨機(jī)偶數(shù),運(yùn)行5個(gè)數(shù)[random.randrange(0,11,2) for i in range(5)][2, 4, 8, 8, 6]
random.sample()
描述:從population樣本或集合中隨機(jī)抽取K個(gè)不重復(fù)的元素形成新的序列。常用于不重復(fù)的隨機(jī)抽樣。返回的是一個(gè)新的序列,不會(huì)破壞原有序列。要從一個(gè)整數(shù)區(qū)間隨機(jī)抽取一定數(shù)量的整數(shù),請(qǐng)使用sample(range(1000000), k=60)類(lèi)似的方法,這非常有效和節(jié)省空間。如果k大于population的長(zhǎng)度,則彈出ValueError異常。語(yǔ)法:random.sample(population, k)注意:與random.choices()的區(qū)別:一個(gè)是選取k次,一個(gè)是選取k個(gè),選取k次的相當(dāng)于選取后又放回,選取k個(gè)則選取后不放回。故random.sample()的k值不能超出集群的元素個(gè)數(shù)。
random.sample(range(1000), k=5)[82, 678, 664, 177, 376]L = [0,1,2,3,4,5]random.sample(L,3)[5, 3, 1]random.sample(L,3)[2, 4, 5]
random.seed()
描述:初始化偽隨機(jī)數(shù)生成器。如果未提供a或者a=None,則使用系統(tǒng)時(shí)間為種子。如果a是一個(gè)整數(shù),則作為種子。偽隨機(jī)數(shù)生成模塊。如果不提供 seed,默認(rèn)使用系統(tǒng)時(shí)間。使用相同的 seed,可以獲得完全相同的隨機(jī)數(shù)序列,常用于算法改進(jìn)測(cè)試。語(yǔ)法:random.seed(a=None, version=2)
# 生成一個(gè)隨機(jī)數(shù)迭代器實(shí)例,與下列的實(shí)例不共享隨機(jī)狀態(tài)a = random.Random()[a.randint(1, 100) for i in range(20)][97, 91, 63, 88, 82, 6, 80, 59, 40, 96, 64, 6, 68, 49, 65, 50, 58, 5, 31, 60]b = random.Random()[b.randint(1, 100) for i in range(20)][46, 53, 89, 1, 48, 21, 45, 26, 89, 96, 43, 85, 21, 78, 8, 38, 54, 1, 27, 56]############################################################################a = random.Random()# 指定相同的隨機(jī)種子,共享隨機(jī)狀態(tài)a.seed(1)[a.randint(1, 100) for i in range(20)][14, 85, 77, 26, 50, 45, 66, 79, 10, 3, 84, 44, 77, 1, 45, 73, 23, 95, 91, 4]b =random.Random()# 指定相同的隨機(jī)種子,共享隨機(jī)狀態(tài)b.seed(1)[b.randint(1, 100) for i in range(20)][14, 85, 77, 26, 50, 45, 66, 79, 10, 3, 84, 44, 77, 1, 45, 73, 23, 95, 91, 4]
random.shuffle()
描述:用于將一個(gè)列表中的元素打亂。只能針對(duì)可變的序列,對(duì)于不可變序列,請(qǐng)使用下面的sample()方法。語(yǔ)法:random.shuffle(x)
L = [0,1,2,3,4,5]random.shuffle(L)L[5, 4, 1, 0, 3, 2]
random.uniform()
描述:產(chǎn)生[a,b]范圍內(nèi)一個(gè)隨機(jī)浮點(diǎn)數(shù)。uniform()的a,b參數(shù)不需要遵循a<=b的規(guī)則,即a小b大也可以,此時(shí)生成[b,a]范圍內(nèi)的隨機(jī)浮點(diǎn)數(shù)。語(yǔ)法:random.uniform(x, y)
random.uniform(10, 11)10.789198208817488
random.triangular()
描述:返回一個(gè)low <= N <=high的三角形分布的隨機(jī)數(shù)。參數(shù)mode指明眾數(shù)出現(xiàn)位置。語(yǔ)法:random.triangular(low, high, mode)
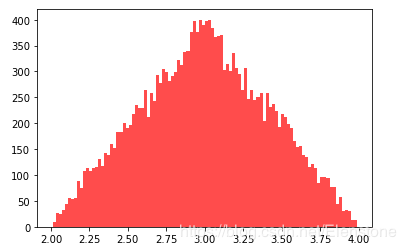
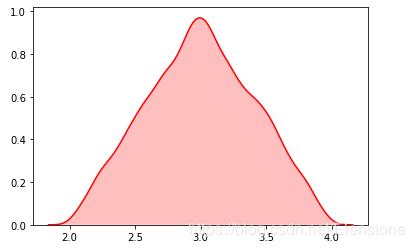
data = [random.triangular(2,4,3) for i in range(20000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
密度圖
random.vonmisesvariate()
描述:卡帕分布語(yǔ)法:vonmisesvariate(mu, kappa)
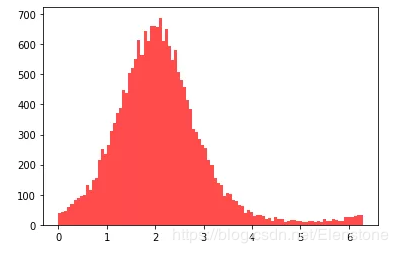
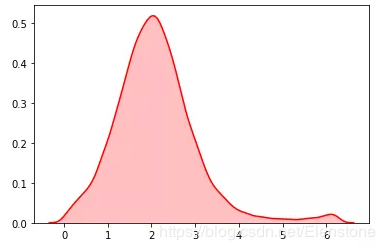
data = [random.vonmisesvariate(2,2) for i in range(20000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
密度圖
random.weibullvariate()
描述:威布爾分布語(yǔ)法:random.weibullvariate(alpha, beta)
data = [random.weibullvariate(1,2) for i in range(20000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
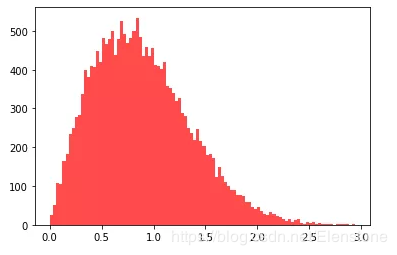
密度圖
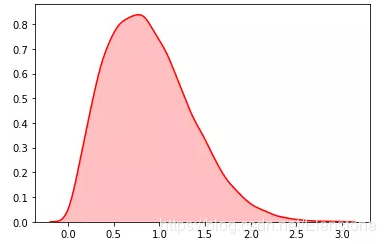
random.betavariate()
描述: β分布語(yǔ)法:random.betavariate(alpha, beta)
data = [random.betavariate(1,2) for i in range(20000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
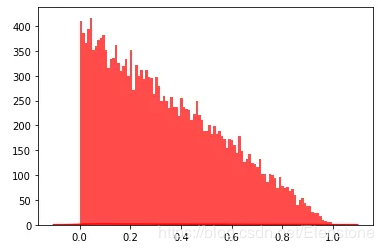
密度圖
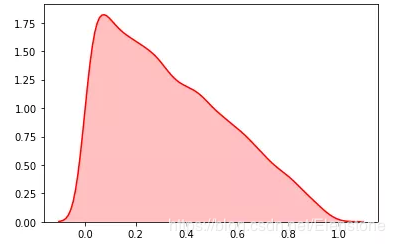
random.expovariate()
描述:指數(shù)分布語(yǔ)法:random.expovariate(lambd)
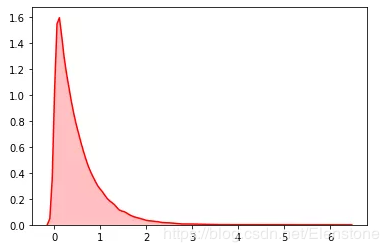
data = [random.expovariate(2) for i in range(50000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
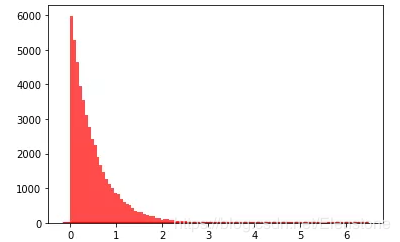
密度圖
random.gammavariate()
描述: 伽馬分布語(yǔ)法:random.gammavariate(alpha, beta)
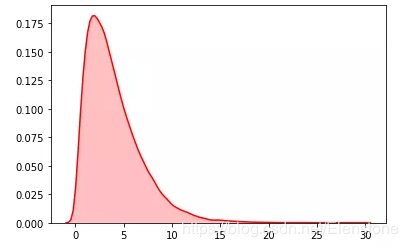
data = [random.gammavariate(2,2) for i in range(50000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
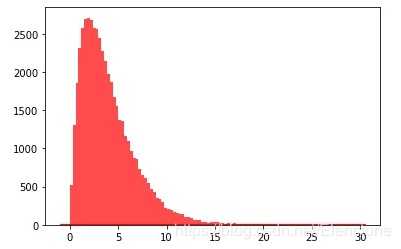
密度圖
random.gauss()
描述:高斯分布語(yǔ)法:random.gauss(mu, sigma)
data = [random.gauss(2,2) for i in range(50000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
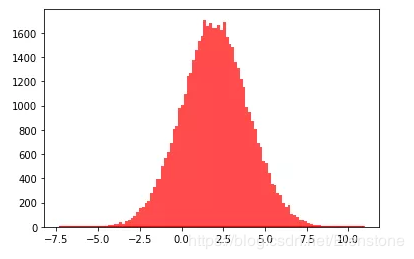
密度圖

random.lognormvariate()
描述:對(duì)數(shù)正態(tài)分布語(yǔ)法:random.lognormvariate(mu, sigma)
data = [random.lognormvariate(4,2) for i in range(50000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
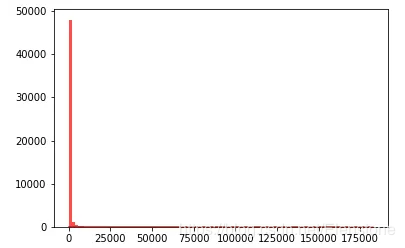
密度圖

random.normalvariate()
描述: 正態(tài)分布語(yǔ)法:random.normalvariate(mu, sigma)
data = [random.normalvariate(2,4) for i in range(20000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
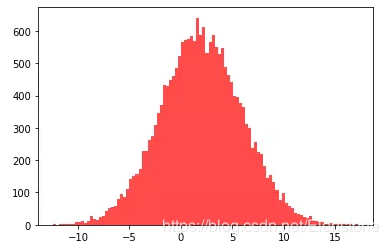
密度圖
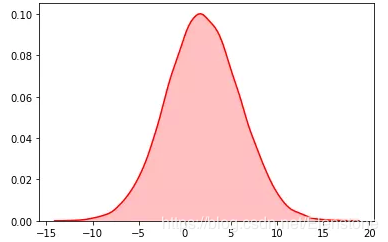
random.paretovariate()
描述:帕累托分布語(yǔ)法:random.paretovariate(alpha)
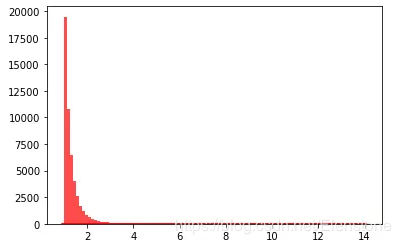
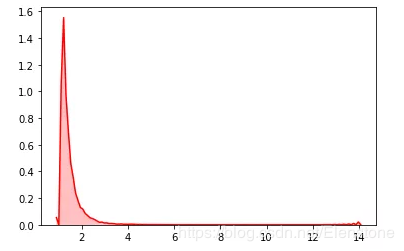
data = [random.paretovariate(4) for i in range(50000)]#直方圖plt.hist(data, bins=100, color='#FF0000', alpha=.7)#密度圖sns.kdeplot(data, shade=True,color='#FF0000')
直方圖
密度圖
到此這篇關(guān)于python隨機(jī)模塊random的22種函數(shù)(小結(jié))的文章就介紹到這了,更多相關(guān)python隨機(jī)模塊random內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. asp讀取xml文件和記數(shù)2. 多個(gè)SpringBoot項(xiàng)目采用redis實(shí)現(xiàn)Session共享功能3. vue 驗(yàn)證兩次輸入的密碼是否一致的方法示例4. 簡(jiǎn)體中文轉(zhuǎn)換為繁體中文的PHP函數(shù)5. CSS自定義滾動(dòng)條樣式案例詳解6. 讓你的PHP同時(shí)支持GIF、png、JPEG7. 每日六道java新手入門(mén)面試題,通往自由的道路第二天8. PHP實(shí)現(xiàn)基本留言板功能原理與步驟詳解9. Django正則URL匹配實(shí)現(xiàn)流程解析10. python利用opencv實(shí)現(xiàn)顏色檢測(cè)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備