解析Linux高性能網絡IO和Reactor模型
在零拷貝機制篇章已介紹過 用戶空間和內核空間和緩沖區,這里就省略了
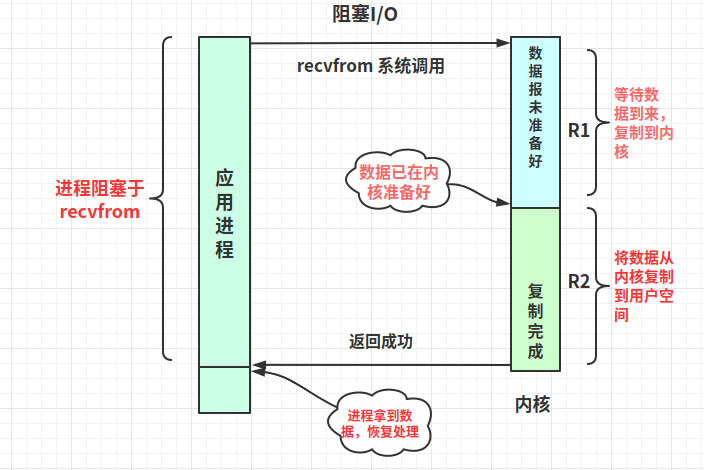
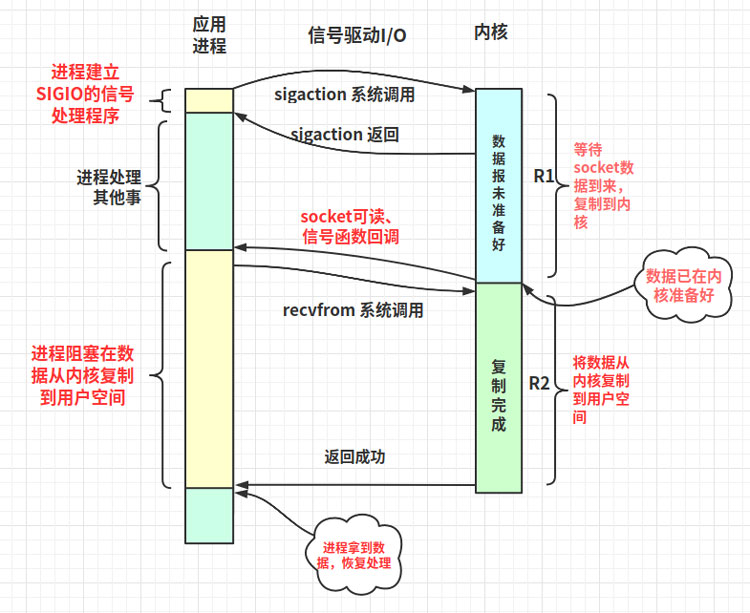
二、網絡IO的讀寫過程 當在用戶空間發起對socket套接字的讀操作時,會導致上下文切換,用戶進程阻塞(R1)等待網絡數據流到來,從網卡復制到內核;(R2)然后從內核緩沖區向用戶進程緩沖區復制。此時進程切換恢復,處理拿到的數據 這里我們給socket讀操作的第一階段起個別名R1,第二階段稱為R2 當在用戶空間發起對socket的send操作時,導致上下文切換,用戶進程阻塞等待(1)數據從用戶進程緩沖區復制到內核緩沖區。數據copy完成,此時進程切換恢復三、Linux五種網絡IO模型3.1、阻塞式I/O (blocking IO)ssize_t recvfrom(int sockfd,void *buf,size_t len,unsigned int flags, struct sockaddr *from,socket_t *fromlen);


int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
1)使用copy_from_user從用戶空間拷貝fd_set到內核空間
2)注冊回調函數__pollwait
3)遍歷所有fd,調用其對應的poll方法(對于socket,這個poll方法是sock_poll,sock_poll根據情況會調用到tcp_poll,udp_poll或者datagram_poll)
4)以tcp_poll為例,其核心實現就是__pollwait,也就是上面注冊的回調函數
5)__pollwait的主要工作就是把current(當前進程)掛到設備的等待隊列中,不同的設備有不同的等待隊列,對于tcp_poll來說,其等待隊列是sk->sk_sleep(注意把進程掛到等待隊列中并不代表進程已經睡眠了)。在設備收到一條消息(網絡設備)或填寫完文件數據(磁盤設備)后,會喚醒設備等待隊列上睡眠的進程,這時current便被喚醒了
6)poll方法返回時會返回一個描述讀寫操作是否就緒的mask掩碼,根據這個mask掩碼給fd_set賦值
7)如果遍歷完所有的fd,還沒有返回一個可讀寫的mask掩碼,則會調用schedule_timeout是調用select的進程(也就是current)進入睡眠
8) 當設備驅動發生自身資源可讀寫后,會喚醒其等待隊列上睡眠的進程。如果超過一定的超時時間(timeout指定),還是沒人喚醒,則調用select的進程會重新被喚醒獲得CPU,進而重新遍歷fd,判斷有沒有就緒的fd
9)把fd_set從內核空間拷貝到用戶空間
select的缺點:
每次調用select,都需要把fd集合從用戶態拷貝到內核態,這個開銷在fd很多時會很大 同時每次調用select都需要在內核遍歷傳遞進來的所有fd,這個開銷在fd很多時也很大 select支持的文件描述符數量太小了,默認是10244.2、epollint epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout); 調用epoll_create,會在內核cache里建個紅黑樹用于存儲以后epoll_ctl傳來的socket,同時也會再建立一個rdllist雙向鏈表用于存儲準備就緒的事件。當epoll_wait調用時,僅查看這個rdllist雙向鏈表數據即可 epoll_ctl在向epoll對象中添加、修改、刪除事件時,是在rbr紅黑樹中操作的,非常快 添加到epoll中的事件會與設備(如網卡)建立回調關系,設備上相應事件的發生時會調用回調方法,把事件加進rdllist雙向鏈表中;這個回調方法在內核中叫做ep_poll_callback
epoll的兩種觸發模式:
epoll有EPOLLLT和EPOLLET兩種觸發模式,LT是默認的模式,ET是“高速”模式(只支持no-block socket)
LT(水平觸發)模式下,只要這個文件描述符還有數據可讀,每次epoll_wait都會觸發它的讀事件 ET(邊緣觸發)模式下,檢測到有I/O事件時,通過 epoll_wait 調用會得到有事件通知的文件描述符,對于文件描述符,如可讀,則必須將該文件描述符一直讀到空(或者返回EWOULDBLOCK),否則下次的epoll_wait不會觸發該事件4.3、epoll相比select的優點解決select三個缺點:
對于第一個缺點:epoll的解決方案在epoll_ctl函數中。每次注冊新的事件到epoll句柄中時(在epoll_ctl中指定EPOLL_CTL_ADD),會把所有的fd拷貝進內核,而不是在epoll_wait的時候重復拷貝。epoll保證了每個fd在整個過程中只會拷貝一次(epoll_wait不需要復制) 對于第二個缺點:epoll為每個fd指定一個回調函數,當設備就緒,喚醒等待隊列上的等待者時,就會調用這個回調函數,而這個回調函數會把就緒的fd加入一個就緒鏈表。epoll_wait的工作實際上就是在這個就緒鏈表中查看有沒有就緒的fd(不需要遍歷) 對于第三個缺點:epoll沒有這個限制,它所支持的FD上限是最大可以打開文件的數目,這個數字一般遠大于2048,舉個例子,在1GB內存的機器上大約是10萬左右,一般來說這個數目和系統內存關系很大epoll的高性能:
epoll使用了紅黑樹來保存需要監聽的文件描述符事件,epoll_ctl增刪改操作快速 epoll不需要遍歷就能獲取就緒fd,直接返回就緒鏈表即可 linux2.6 之后使用了mmap技術,數據不在需要從內核復制到用戶空間,零拷貝4.4、關于epoll的IO模型是同步異步的疑問概念定義:
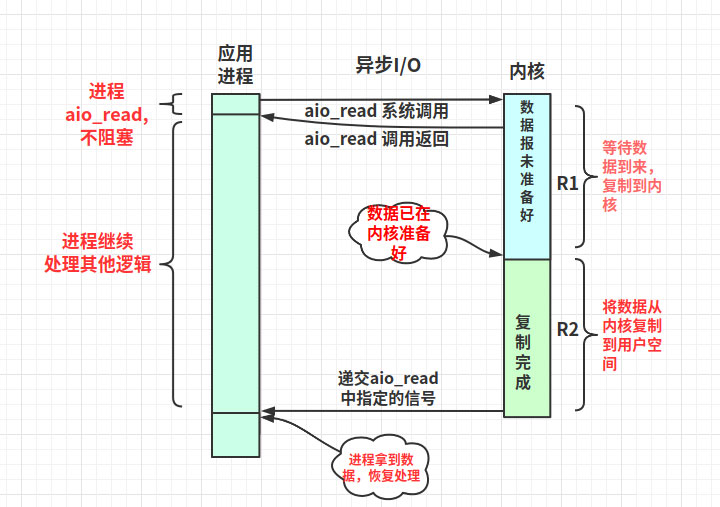
同步I/O操作:導致請求進程阻塞,直到I/O操作完成 異步I/O操作:不導致請求進程阻塞,異步只用處理I/O操作完成后的通知,并不主動讀寫數據,由系統內核完成數據的讀寫 阻塞,非阻塞:進程/線程要訪問的數據是否就緒,進程/線程是否需要等待異步IO的概念是要求無阻塞I/O調用。前面有介紹到I/O操作分兩階段:R1等待數據準備好。R2從內核到進程拷貝數據。雖然epoll在2.6內核之后采用mmap機制,使得其在R2階段不需要復制,但是它在R1還是阻塞的。因此歸類到同步IO
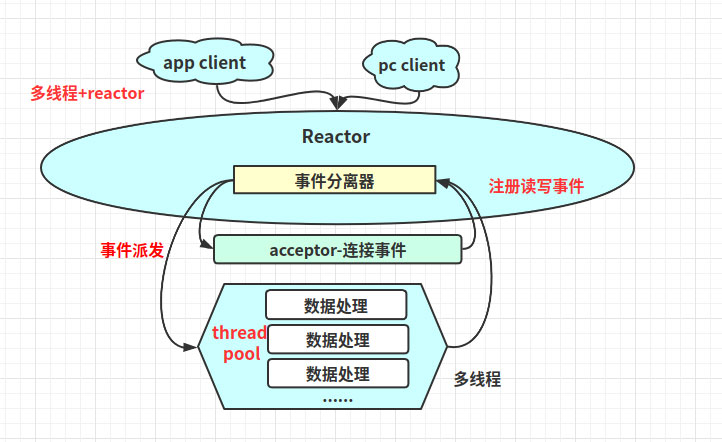
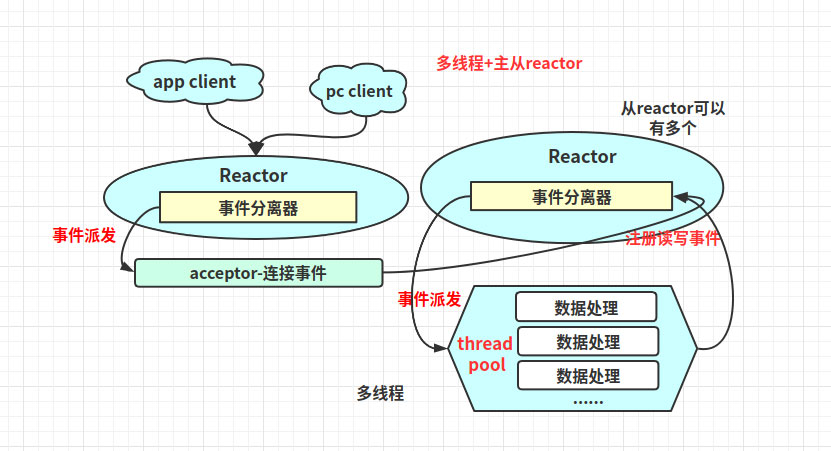
五、Reactor模型Reactor的中心思想是將所有要處理的I/O事件注冊到一個中心I/O多路復用器上,同時主線程/進程阻塞在多路復用器上;一旦有I/O事件到來或是準備就緒,多路復用器返回,并將事先注冊的相應I/O事件分發到對應的處理器中
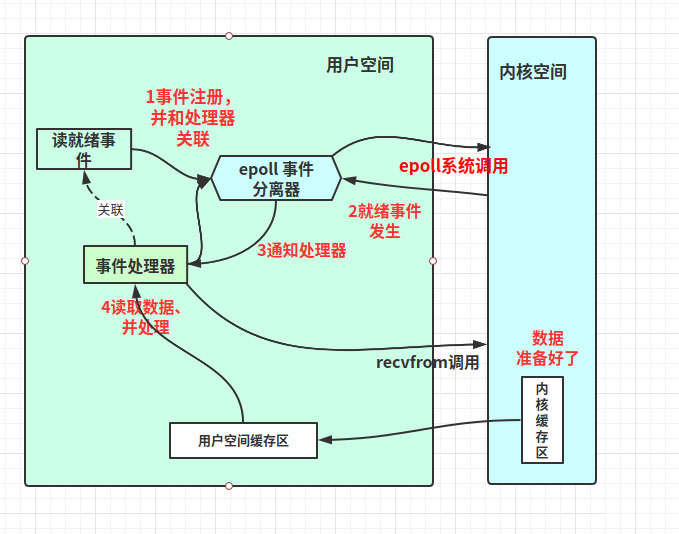
5.1、相關概念介紹 事件:就是狀態;比如:讀就緒事件指的是我們可以從內核讀取數據的狀態 事件分離器:一般會把事件的等待發生交給epoll、select;而事件的到來是隨機,異步的,所以需要循環調用epoll,在框架里對應封裝起來的模塊就是事件分離器(簡單理解為對epoll封裝) 事件處理器:事件發生后需要進程或線程去處理,這個處理者就是事件處理器,一般和事件分離器是不同的線程5.2、Reactor的一般流程1)應用程序在事件分離器注冊讀寫就緒事件和讀寫就緒事件處理器
2)事件分離器等待讀寫就緒事件發生
3)讀寫就緒事件發生,激活事件分離器,分離器調用讀寫就緒事件處理器
4)事件處理器先從內核把數據讀取到用戶空間,然后再處理數據

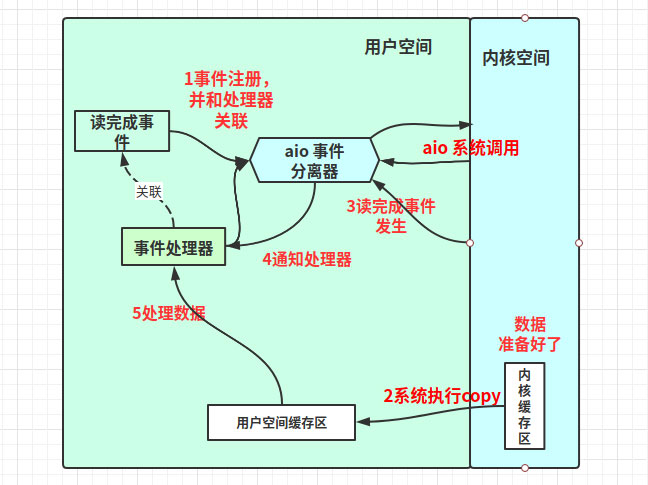
1)應用程序在事件分離器注冊讀完成事件和讀完成事件處理器,并向系統發出異步讀請求
2)事件分離器等待讀事件的完成
3)在分離器等待過程中,系統利用并行的內核線程執行實際的讀操作,并將數據復制進程緩沖區,最后通知事件分離器讀完成到來
4)事件分離器監聽到讀完成事件,激活讀完成事件的處理器
5)讀完成事件處理器直接處理用戶進程緩沖區中的數據
以上就是解析Linux高性能網絡IO和Reactor模型的詳細內容,更多關于Linux高性能網絡IO和Reactor模型的資料請關注好吧啦網其它相關文章!
相關文章:
 網公網安備
網公網安備