Python jieba結(jié)巴分詞原理及用法解析
1、簡要說明
結(jié)巴分詞支持三種分詞模式,支持繁體字,支持自定義詞典
2、三種分詞模式
全模式:把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義
精簡模式:把句子最精確的分開,不會添加多余單詞,看起來就像是把句子分割一下
搜索引擎模式:在精簡模式下,對長詞再度切分
# -*- encoding=utf-8 -*-import jiebaif __name__ == ’__main__’: str1 = ’我去北京天安門廣場跳舞’ a = jieba.lcut(str1, cut_all=True) # 全模式 print(’全模式:{}’.format(a)) b = jieba.lcut(str1, cut_all=False) # 精簡模式 print(’精簡模式:{}’.format(b)) c = jieba.lcut_for_search(str1) # 搜索引擎模式 print(’搜索引擎模式:{}’.format(c))
運(yùn)行
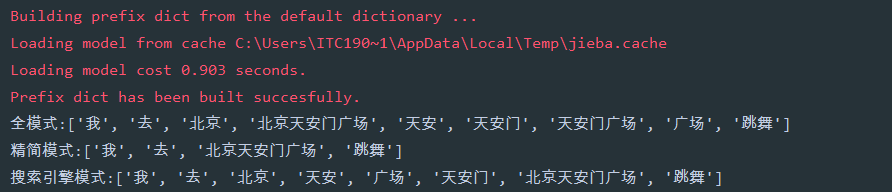
3、某個詞語不能被分開
# -*- encoding=utf-8 -*-import jiebaif __name__ == ’__main__’: str1 = ’桃花俠大戰(zhàn)菊花怪’ b = jieba.lcut(str1, cut_all=False) # 精簡模式 print(’精簡模式:{}’.format(b)) # 如果不把桃花俠分開 jieba.add_word(’桃花俠’) d = jieba.lcut(str1) # 默認(rèn)是精簡模式 print(d)
運(yùn)行
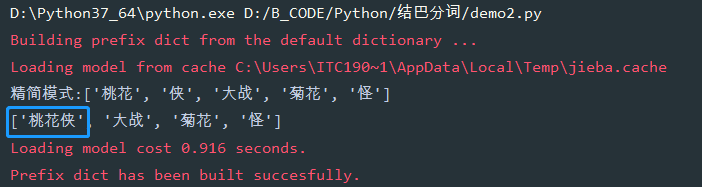
4、 某個單詞必須被分開
# -*- encoding=utf-8 -*-import jiebaif __name__ == ’__main__’: # HMM參數(shù),默認(rèn)為True ’’’HMM 模型,即隱馬爾可夫模型(Hidden Markov Model, HMM),是一種基于概率的統(tǒng)計(jì)分析模型, 用來描述一個系統(tǒng)隱性狀態(tài)的轉(zhuǎn)移和隱性狀態(tài)的表現(xiàn)概率。 在 jieba 中,對于未登錄到詞庫的詞,使用了基于漢字成詞能力的 HMM 模型和 Viterbi 算法, 其大致原理是: 采用四個隱含狀態(tài),分別表示為單字成詞,詞組的開頭,詞組的中間,詞組的結(jié)尾。 通過標(biāo)注好的分詞訓(xùn)練集,可以得到 HMM 的各個參數(shù),然后使用 Viterbi 算法來解釋測試集,得到分詞結(jié)果。 ’’’ str1 = ’桃花俠大戰(zhàn)菊花怪’ b = jieba.lcut(str1, cut_all=False, HMM=False) # 精簡模式,且不使用HMM模型 print(’精簡模式:{}’.format(b)) # 分開大戰(zhàn)為大和戰(zhàn) jieba.suggest_freq((’大’, ’戰(zhàn)’), True) e = jieba.lcut(str1, HMM=False) # 不使用HMM模型 print(’分開:{}’.format(e))
運(yùn)行
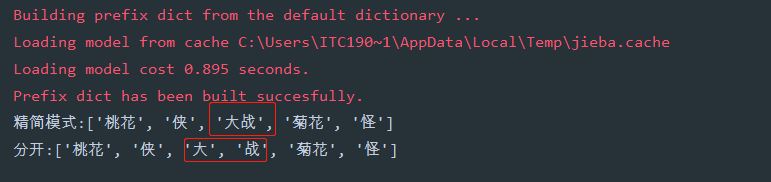
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. XML入門的常見問題(三)2. .NET Core 分布式任務(wù)調(diào)度ScheduleMaster詳解3. 不要在HTML中濫用div4. HTML5實(shí)戰(zhàn)與剖析之觸摸事件(touchstart、touchmove和touchend)5. CSS清除浮動方法匯總6. HTTP協(xié)議常用的請求頭和響應(yīng)頭響應(yīng)詳解說明(學(xué)習(xí))7. XML在語音合成中的應(yīng)用8. ASP將數(shù)字轉(zhuǎn)中文數(shù)字(大寫金額)的函數(shù)9. XML 非法字符(轉(zhuǎn)義字符)10. jscript與vbscript 操作XML元素屬性的代碼
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備