python爬蟲利器之requests庫的用法(超全面的爬取網頁案例)
利用pip安裝:pip install requests
基本請求
req = requests.get('https://www.baidu.com/')req = requests.post('https://www.baidu.com/')req = requests.put('https://www.baidu.com/')req = requests.delete('https://www.baidu.com/')req = requests.head('https://www.baidu.com/')req = requests.options(https://www.baidu.com/)1.get請求
參數是字典,我們可以傳遞json類型的參數:
import requestsfrom fake_useragent import UserAgent#請求頭部庫headers = {'User-Agent':UserAgent().random}#獲取一個隨機的請求頭url = 'https://www.baidu.com/s'#網址params={ 'wd':'豆瓣' #網址的后綴}requests.get(url,headers=headers,params=params)

返回了狀態碼,所以我們要想獲取內容,需要將其轉成text:
#get請求headers = {'User-Agent':UserAgent().random}url = 'https://www.baidu.com/s'params={ 'wd':'豆瓣'}response = requests.get(url,headers=headers,params=params)response.text2.post 請求
參數也是字典,也可以傳遞json類型的參數:
import requests from fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().random}url = 'https://www.baidu.cn/index/login/login' #登錄賬號密碼的網址params = { 'user':'1351351335',#賬號 'password':'123456'#密碼}response = requests.post(url,headers=headers,data=params)response.text
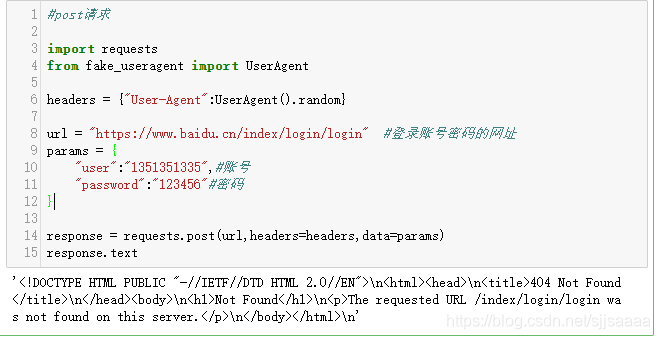
因為這里需要一個登錄的網頁,我這里就隨便用了一個,沒有登錄,所以顯示的結果是這樣的,如果想要測試登錄的效果,請找一個登錄的頁面去嘗試一下。
3.IP代理采集時為避免被封IP,經常會使用代理,requests也有相應 的proxies屬性。
#IP代理import requests from fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().random}url = 'http://httpbin.org/get' #返回當前IP的網址proxies = { 'http':'http://yonghuming:[email protected]:8088'#http://用戶名:密碼@IP:端口號 #'http':'https://182.145.31.211:4224'# 或者IP:端口號}requests.get(url,headers=headers,proxies=proxies)
代理IP可以去:快代理去找,也可以去購買。http://httpbin.org/get。這個網址是查看你現在的信息:

可以通過timeout屬性設置超時時間,一旦超過這個時間還沒獲取到響應內容,就會提示錯誤。
#設置訪問時間requests.get('http://baidu.com/',timeout=0.1)

ssl驗證。
import requests from fake_useragent import UserAgent #請求頭部庫url = 'https://www.12306.cn/index/' #需要證書的網頁地址headers = {'User-Agent':UserAgent().random}#獲取一個隨機請求頭requests.packages.urllib3.disable_warnings()#禁用安全警告response = requests.get(url,verify=False,headers=headers)response.encoding = 'utf-8' #用來顯示中文,進行轉碼response.text

import requestsfrom fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().chrome}login_url = 'https://www.baidu.cn/index/login/login' #需要登錄的網頁地址params = { 'user':'yonghuming',#用戶名 'password':'123456'#密碼}session = requests.Session() #用來保存cookie#直接用session 歹意requests response = session.post(login_url,headers=headers,data=params)info_url = 'https://www.baidu.cn/index/user.html' #登錄完賬號密碼以后的網頁地址resp = session.get(info_url,headers=headers)resp.text
因為我這里沒有使用需要賬號密碼的網頁,所以顯示這樣:

我獲取了一個智慧樹的網頁
#cookie import requestsfrom fake_useragent import UserAgentheaders = {'User-Agent':UserAgent().chrome}login_url = 'https://passport.zhihuishu.com/login?service=https://onlineservice.zhihuishu.com/login/gologin' #需要登錄的網頁地址params = { 'user':'12121212',#用戶名 'password':'123456'#密碼}session = requests.Session() #用來保存cookie#直接用session 歹意requests response = session.post(login_url,headers=headers,data=params)info_url = 'https://onlne5.zhhuishu.com/onlinWeb.html#/stdetInex' #登錄完賬號密碼以后的網頁地址resp = session.get(info_url,headers=headers)resp.encoding = 'utf-8'resp.text

代碼 含義 resp.json() 獲取響應內容 (以json字符串) resp.text 獲取相應內容(以字符串) resp.content 獲取響應內容(以字節的方式) resp.headers 獲取響應頭內容 resp.url 獲取訪問地址 resp.encoding 獲取網頁編碼 resp.request.headers 請求頭內容 resp.cookie 獲取cookie
到此這篇關于python爬蟲利器之requests庫的用法(超全面的爬取網頁案例)的文章就介紹到這了,更多相關python爬蟲requests庫用法內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備